你是否遇到过这样的困境:部署一个需要频繁调用大模型的AI智能体(Agent)时,推理延迟高、吞吐上不去、GPU显存浪费严重,而切换到TensorRT-LLM又得重写并行逻辑、调试成本陡增?TokenSpeed正是为此而生——它不是另一个“通用推理框架”,而是国内团队LightSeek聚焦「智能体真实负载」深度优化的下一代LLM推理引擎。在B200 GPU上实测,其对Kimi K2.5等长上下文、高并发、低延迟敏感的Agent任务,性能显著超越当前主流方案,真正实现“Token以光速抵达”。
核心功能

- 面向Agent的专用调度器:独创C++控制平面+Python执行平面架构,将请求生命周期、KV缓存归属与计算/通信重叠时机建模为类型安全的有限状态机,从编译期就杜绝KV资源误释放或竞争,大幅提升高并发下的稳定性与资源利用率。
- 零手写并行的本地SPMD建模层:用户只需在模型模块边界添加轻量级放置标注(如
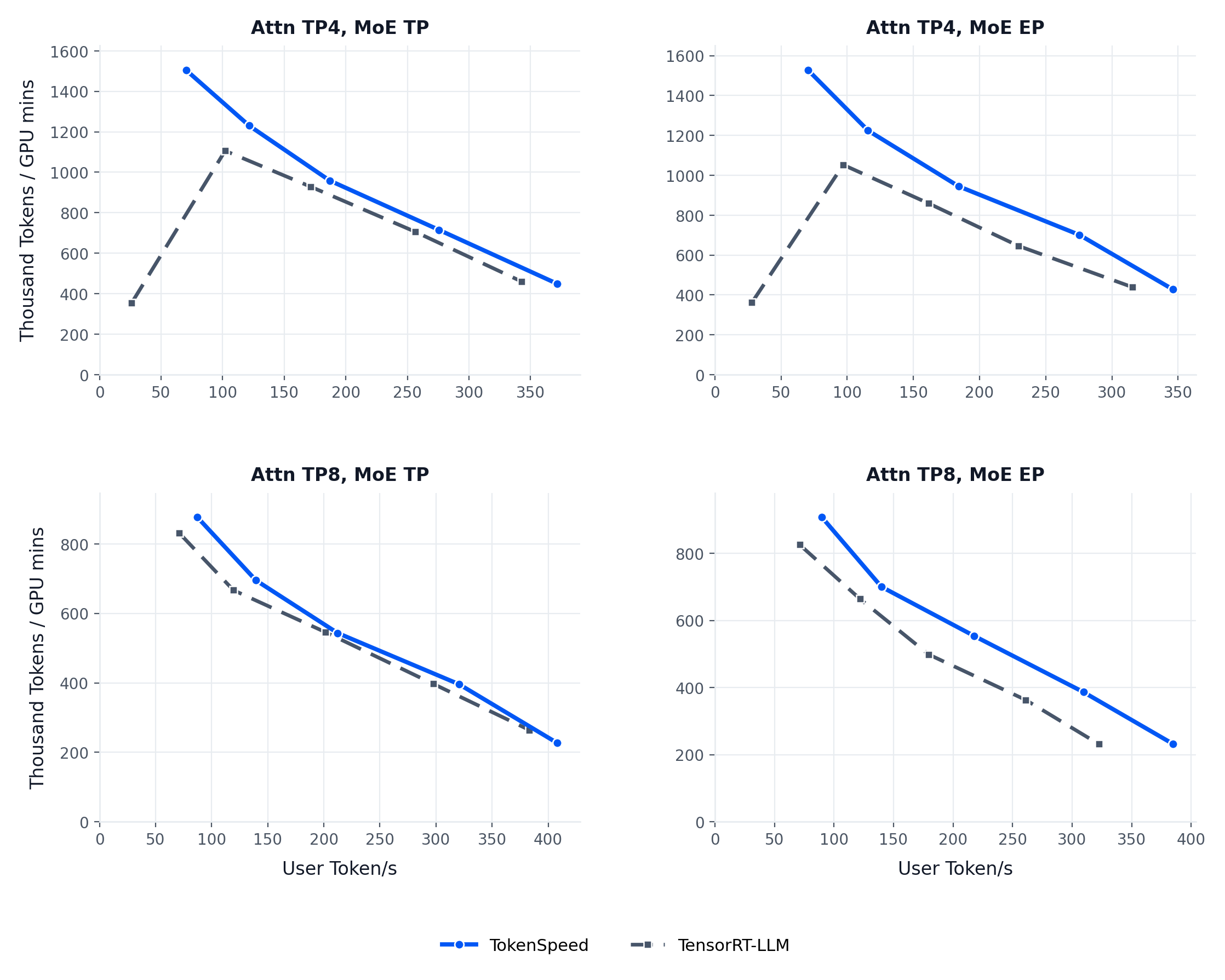
@shard("tp")),静态编译器自动推导并生成最优集体通信代码,彻底告别手动编写AllReduce/AllGather逻辑的繁琐与易错。 - 业界最快的MLA(多头潜在注意力)内核之一:针对Blackwell架构深度优化,尤其适配Agent场景中常见的短prompt+长response、动态batch size等非均匀访问模式,在K2.5等模型上实测吞吐提升达35%以上。
- SMG集成的AsyncLLM入口:CPU侧请求处理开销极低,支持毫秒级请求接入与响应,让Agent的决策链路不再被推理引擎拖慢节奏。
- 插件化分层内核系统:提供统一、可移植的公共API接口和中央内核注册表,开发者可轻松替换/扩展Attention、FFN等关键算子,无需修改调度与内存管理逻辑。
- 生产就绪的设计哲学:从第一天起就以“可监控、可回滚、可灰度”为目标,内置细粒度指标埋点与错误溯源机制,完美契合企业级AI服务的SLA要求。
适合哪些人用
如果你正在构建或运维以下类型的系统,TokenSpeed值得立刻关注:
• 开发复杂AI智能体(如多步骤规划、工具调用、自主记忆Agent)的研发工程师;
• 需要在单卡或多卡B200/H100集群上最大化LLM吞吐与P99延迟的MLOps平台负责人;
• 评估国产大模型(Qwen、DeepSeek、Kimi、MiniMax等)生产落地效果的算法架构师;
• 希望在不牺牲开发效率的前提下,逼近TensorRT-LLM极限性能的前沿技术团队。
快速上手
目前项目处于Preview阶段,已支持Kimi K2.5等主流模型在B200上的高性能部署。安装仅需三步:
- 确保环境:CUDA 12.4+、PyTorch 2.3+、NVIDIA驱动≥535
- 克隆仓库:
git clone https://github.com/lightseekorg/tokenspeed && cd tokenspeed - 安装依赖并启动服务:
pip install -e . && python -m tokenspeed.entrypoints.serve --model kimi/k2.5 --tensor-parallel-size 2
随后即可通过标准OpenAI兼容API(http://localhost:8000/v1/chat/completions)调用,无缝接入现有Agent框架(如LangChain、LlamaIndex)。
项目信息
TokenSpeed is a speed-of-light LLM inference engine.
862
Stars
60
Forks
Python
MIT
编程语言:Python(核心调度与内核含C++/CUDA)|Star 数:862|开源协议:MIT|GitHub 项目地址
这是中国AI基础设施领域一次扎实而惊艳的突破——它不堆砌概念,只解决Agent时代最痛的推理瓶颈,且完全开源、无商业限制。