你是否想过,有一天AI不仅能听懂你的指令、读懂网页文字,还能像真人一样“看见”屏幕、点击按钮、拖拽文件、操作软件?UI-TARS-desktop 正是这样一款革命性的开源工具——它不是另一个聊天机器人,而是一个运行在你本地电脑上的“视觉+交互”双模态AI智能体。它让大语言模型(LLM)和视觉语言模型(VLM)真正具备了“看屏幕、控鼠标、用软件”的能力,把AI从对话框里解放出来,直接融入你的日常办公与开发流程。
核心功能

- 原生桌面GUI自动化:无需网页环境,直接接管Windows/macOS/Linux桌面界面,识别窗口、按钮、输入框等UI元素,完成真实操作系统级操作(如打开微信、截图上传、填写表格)
- 多模态实时理解:结合OCR文字识别与视觉语言模型(VLM),同步理解屏幕截图中的图像布局、文字内容与交互状态,实现“所见即所控”
- 浏览器深度协同:自动操作Chrome/Firefox等主流浏览器,支持登录、表单填写、数据抓取、多标签页切换等复杂Web任务,比传统爬虫更鲁棒、比RPA更智能
- 本地化隐私优先:所有视觉推理与动作决策均在本地完成,敏感截图不上传云端,企业合规与个人隐私双重保障
- 模块化Agent架构:基于MCP(Model Control Protocol)标准设计,可灵活接入Qwen、GLM、Claude等任意本地或远程大模型,也支持自定义工具链扩展
- 开箱即用的可视化界面:提供简洁直观的桌面客户端,支持自然语言指令输入(如“把桌面上所有PDF发给张三邮箱”)、操作过程回放与步骤调试,零代码也能上手
适合哪些人用
这款工具特别适合三类用户:一是效率至上的知识工作者——运营、HR、财务等需频繁跨系统录入/导出数据的岗位;二是开发者与AI工程师——快速验证GUI Agent能力、构建垂直领域自动化工作流、或为自有产品集成智能操作层;三是技术爱好者与学生——深入理解多模态Agent底层原理,在本地跑通一个真正“能动手”的AI系统,远超纯文本Demo的学习价值。
快速上手
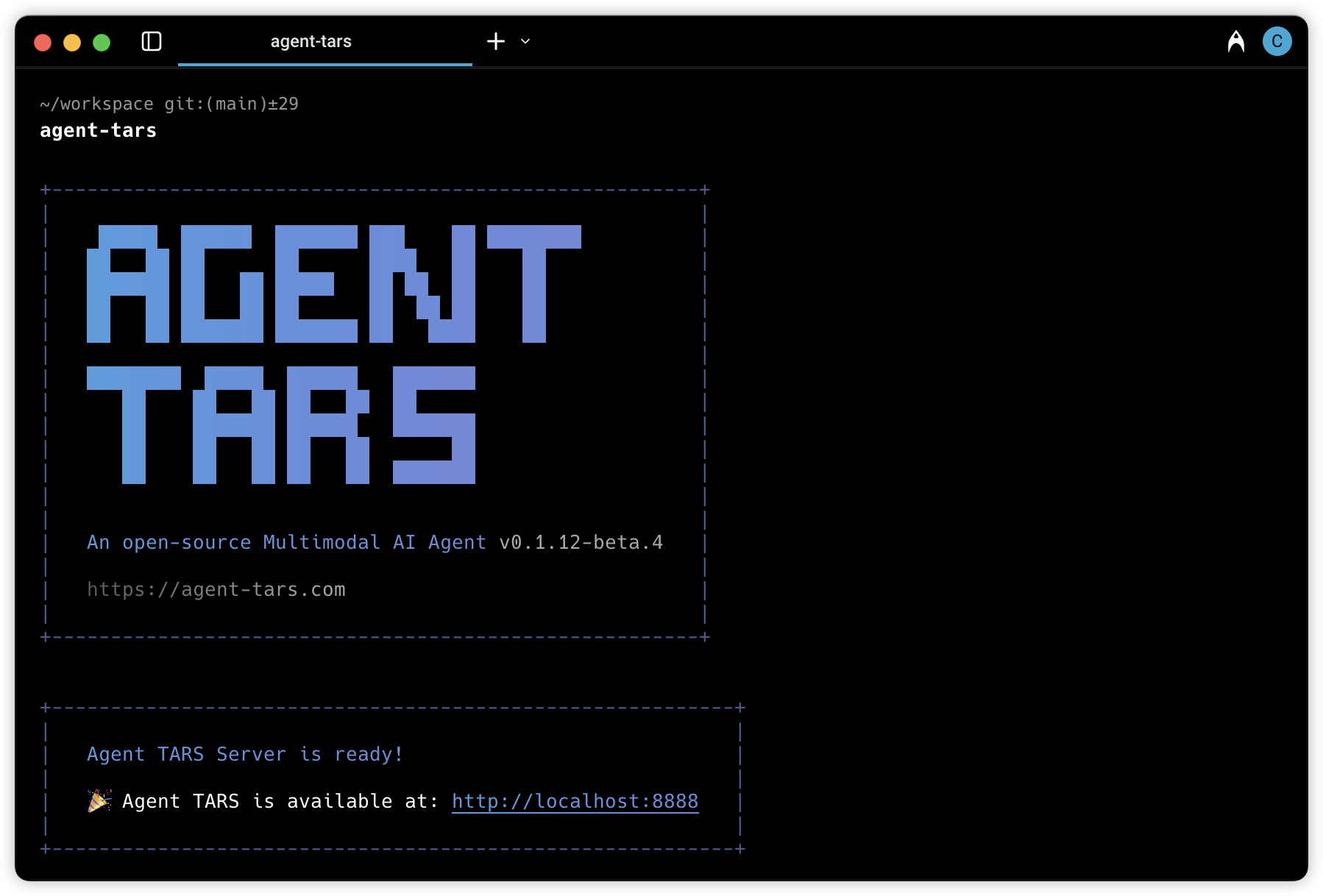
![]()
项目已编译好跨平台安装包(macOS ARM/x64、Windows x64、Linux x64),访问Releases页面下载最新版本,双击安装即可启动。首次运行会引导配置本地大模型(推荐Ollama一键部署Qwen2-VL或Phi-3-vision)或连接API服务。输入中文指令如“帮我查今天北京天气并截图保存到桌面”,AI将自动打开浏览器、搜索、截图、保存——整个过程全程可视化,每一步都可暂停、重试、查看日志。详细文档见官网:ui-tars.com
项目信息
The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra
编程语言:TypeScript|GitHub Star 数:31,074|开源协议:Apache-2.0|GitHub 项目地址
这不是又一个概念Demo,而是字节跳动已在内部规模化落地的生产力基础设施——如果你厌倦了复制粘贴、反复点选、在多个软件间手动搬运数据,那么UI-TARS-desktop就是那个让你第一次真切感受到“AI真的开始替我干活了”的开源利器。