你是否好奇 ChatGPT 这类大语言模型(LLM)背后究竟是怎么工作的?不是调用 API,也不是魔改 Hugging Face 模型,而是真正从张量运算、反向传播、词嵌入、注意力机制开始,一行行代码亲手搭建一个可运行的 GPT 类模型?这个 GitHub 项目就是为此而生——它不是简化版玩具,而是一套经过教学验证、完整覆盖预训练与微调全流程的 PyTorch 实现,带你像造轮子一样理解 LLM 的每一层“血肉”。
核心功能

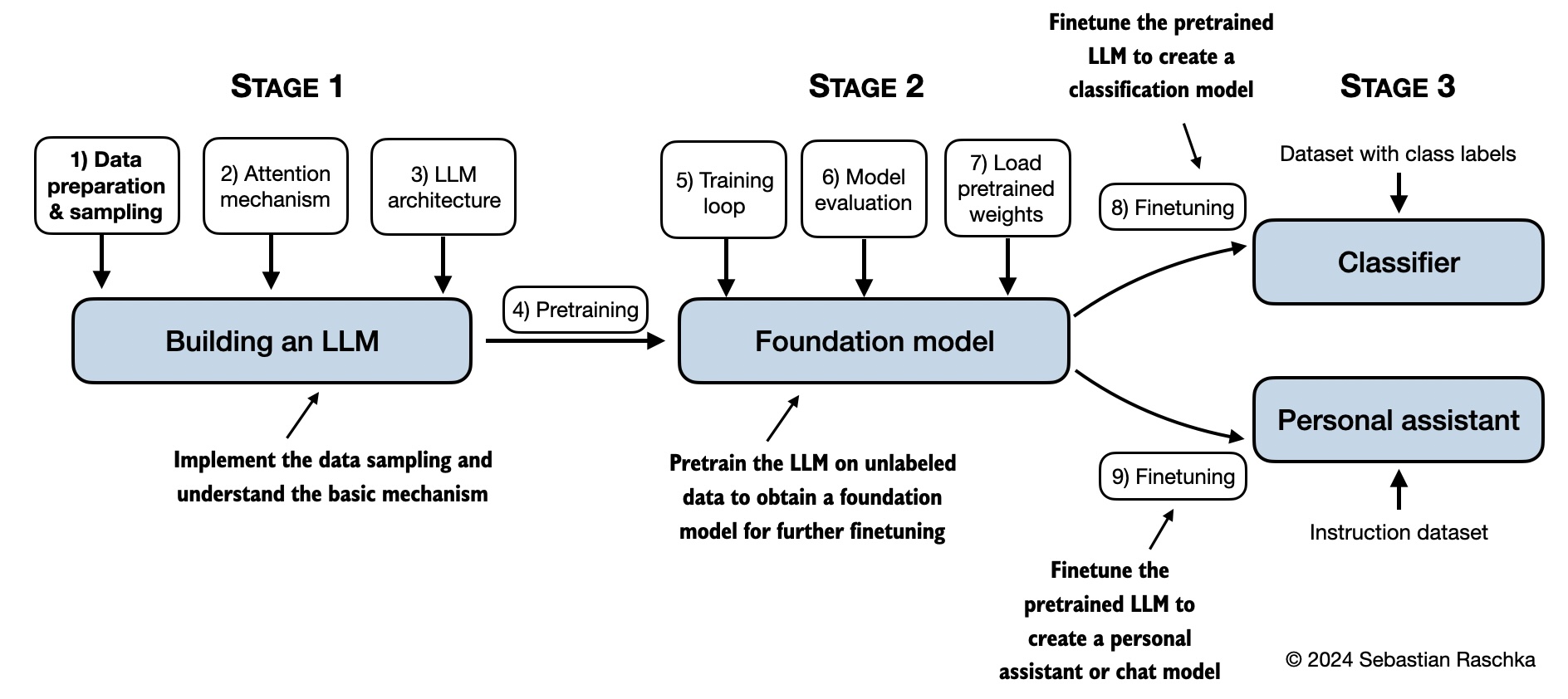
- 逐模块手写 GPT 架构:从最基础的线性层、LayerNorm、多头自注意力(Multi-Head Attention),到完整的 Transformer 解码器堆叠,全部用原生 PyTorch 实现,无黑盒封装
- 端到端训练流程演示:包含数据预处理(Byte-Pair Encoding)、分布式数据加载、梯度裁剪、学习率调度、混合精度训练等工业级训练技巧
- 小规模但可运行的完整模型:提供参数量约 1000 万的轻量 GPT 模型,在消费级显卡(如 RTX 4090)上即可完成预训练与指令微调,真正“跑得起来”
- 支持主流模型权重加载与微调:提供工具脚本,可加载 Hugging Face 上的 LLaMA、Phi-3、TinyLlama 等开源模型权重,进行 LoRA 或全参数微调,打通学习与实战
- 配套 Jupyter Notebook 教学体系:每个关键概念(如 Rotary Positional Embedding、FlashAttention 原理)都配有可视化图解 + 可交互代码单元,边读边跑、即时验证
- 面向教育的工程设计:代码高度模块化、注释详尽、错误提示友好,并内置调试钩子(如梯度监控、注意力热力图可视化),大幅降低初学者认知负荷
适合哪些人用

如果你是:
• AI 学习者:正在系统学习深度学习与 NLP,厌倦了“调包即正义”,渴望真正搞懂 Transformer 为什么有效;
• 高校学生/研究生:需要复现模型细节做课程项目或毕业设计,希望代码可读、可调试、可扩展;
• 工程师转型者:有 Python 和 PyTorch 基础,想快速切入大模型底层开发,为后续参与 MoE、推理优化、模型压缩打下坚实基础;
• 技术讲师/课程设计者:寻找一套结构清晰、难度渐进、附带丰富图示的教学代码库,用于开设 LLM 实战课。
那么,这个项目就是为你量身打造的“LLM 操作系统说明书”。
快速上手
无需购买书籍也可立即实践!项目完全开源免费:
- 克隆仓库:
git clone https://github.com/rasbt/LLMs-from-scratch.git - 安装依赖(建议 Python ≥3.9):
pip install -r requirements.txt(含 torch、transformers、datasets、accelerate 等) - 启动 Jupyter:
jupyter notebook,依次运行ch01/到ch07/目录下的 Notebook(每章对应书中的一个核心章节) - 首次运行推荐从
ch02/02_gpt_from_scratch.ipynb开始——仅用 200 行代码实现一个能生成连贯文本的微型 GPT,5 分钟内见证奇迹 - 进阶可尝试
ch06/中的 LoRA 微调实战,用不到 1GB 显存让模型学会写诗或回答中文问答
项目信息
rasbt/LLMs-from-scratch
GitHub
Implement a ChatGPT-like LLM in PyTorch from scratch, step by step
93.1k
今日 +337 stars today
Stars
14.3k
Forks
Jupyter Notebook
NOASSERTION
编程语言:Jupyter Notebook + Python + PyTorch|GitHub Star 数:93,115|开源协议:未明确声明(NOASSERTION)|GitHub 项目地址
这不仅是代码仓库,更是一份用可执行文字写就的 LLM 内功心法——当你亲手写出第一个 attention score 矩阵,调试通第一个梯度回传,你会真正明白:所谓“大模型”,不过是无数个精妙设计的小模块,在数学与工程的双重约束下,共同奏响的智能协奏曲。