还在为“这个7B模型能不能在M2 Mac上跑起来?”“RTX 4060能流畅跑13B还是得降级到3B?”而反复查文档、试错编译、崩溃重装?llmfit 就是专治这种“模型焦虑”的终端利器——它不训练模型,也不提供API,而是像一位懂硬件、熟GGUF、通晓20+推理后端的AI装机顾问,用一条命令,秒级扫描你的CPU/GPU/内存配置,从200+主流开源大模型中精准筛选出真正能在你机器上“开箱即跑、稳定生成”的选项。告别盲目下载、编译失败和OOM崩溃,让本地大模型真正回归“可用”。
核心功能

- 全栈硬件感知:自动识别CPU型号(Intel/AMD/Apple Silicon)、GPU显存容量(NVIDIA/AMD/Metal/MLX)、系统内存与架构(x86_64/aarch64),连MacBook Air的M1芯片和最新RTX 5090预设都已内置
- 海量模型智能匹配:内置超200个GGUF格式模型(Llama 3、Phi-3、Qwen2、DeepSeek-Coder、Gemma等)及对应量化级别(Q2_K, Q4_K_M, Q6_K, IQ1_S等),按你的硬件实时计算显存占用与推理速度预估
- 多后端无缝支持:原生兼容llama.cpp、Ollama、LM Studio、MLX(Apple)、LocalAI、Unsloth、KTransformers等主流本地推理框架,输出可直接复制粘贴的启动命令
- 真实社区性能排行榜:按硬件分组展示全球用户实测数据——按
b键即可查看RTX 4090跑Qwen2-7B的实测tok/s、首token延迟(TTFT)和VRAM峰值,买卡前先看真实表现 - 交互式硬件模拟:无需换设备!按
H键进入硬件预设模式,快速切换RTX 3060 / M2 Max / WSL2等27+配置,横向对比不同平台下的模型兼容性与性能落差 - 极简单二进制部署:Rust编写,零依赖,Linux/macOS/Windows全平台静态编译,下载即用,无Python环境冲突,无CUDA版本烦恼
适合哪些人用
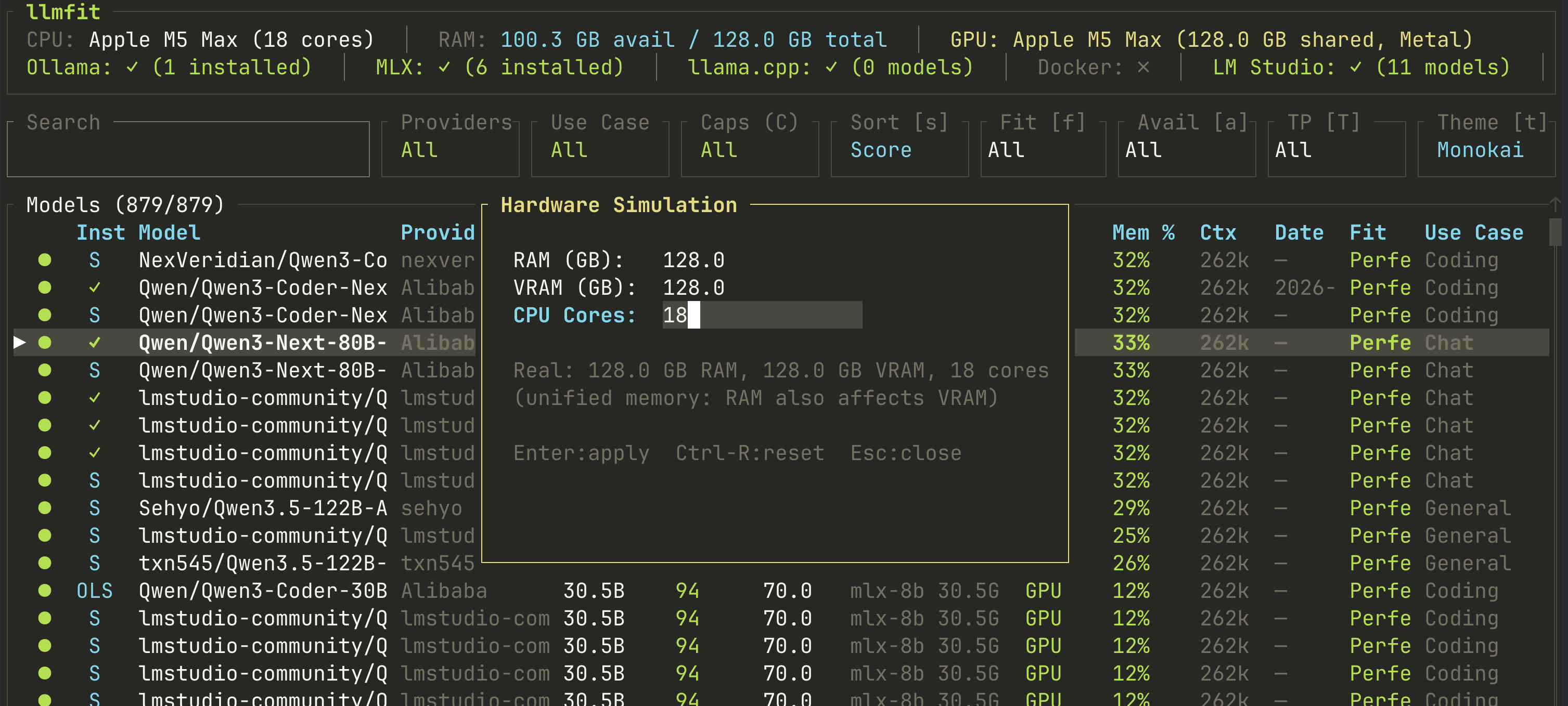
如果你是——刚入门本地AI的开发者,被各种量化格式和后端绕晕;想在旧笔记本或MacBook上跑模型的学生/研究者,不想花三天折腾编译;需要为客户快速验证硬件适配性的解决方案工程师;或者正纠结“该升级显卡还是换Mac”的技术爱好者——llmfit就是为你省下数十小时试错时间的必备工具。它不替代你学习原理,但让你第一次运行就成功。
快速上手
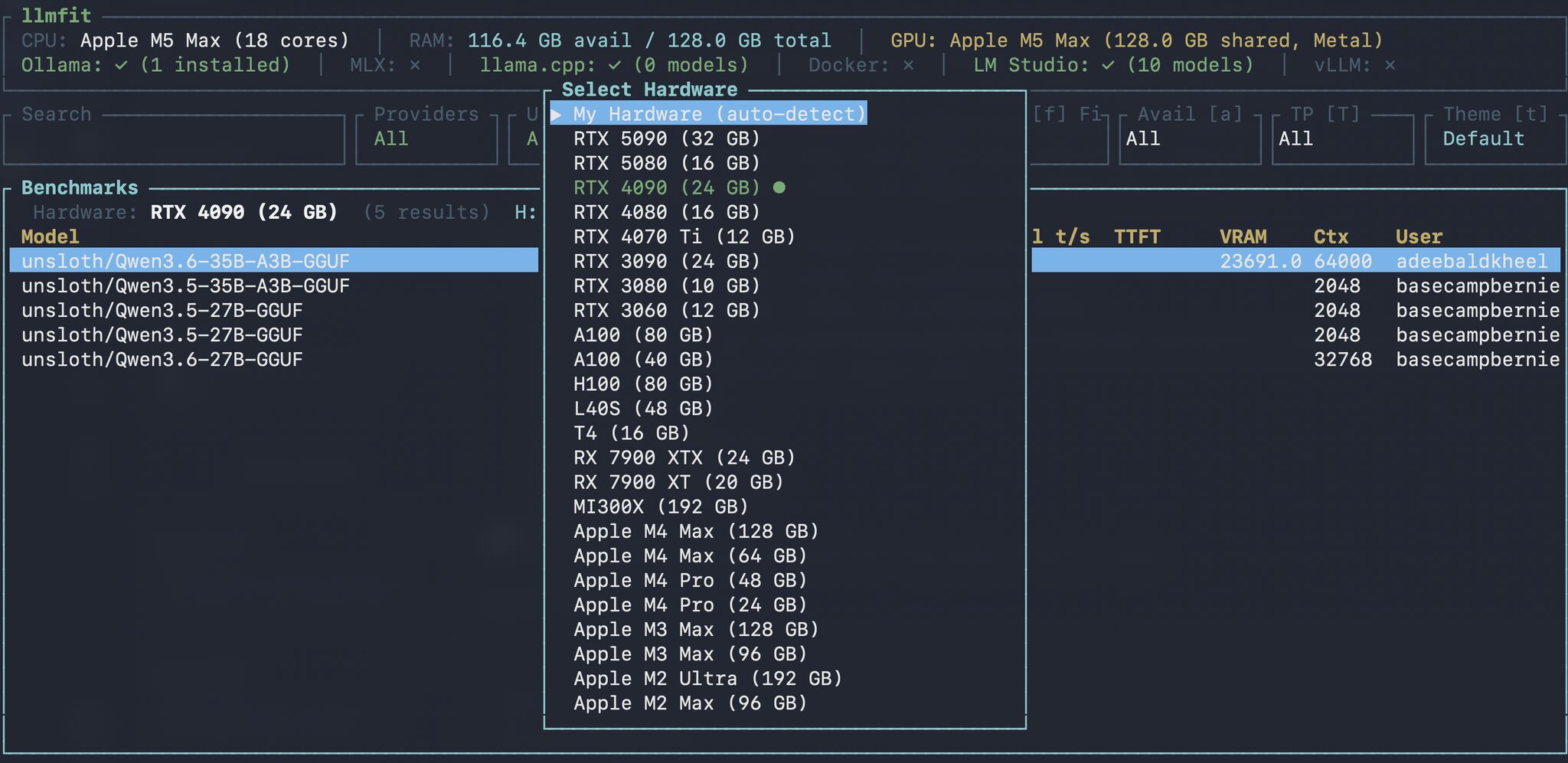
只需两步:
- 安装(任选其一):
• macOS/Linux:curl -fsSL https://raw.githubusercontent.com/AlexsJones/llmfit/main/install.sh | sh
• Windows(PowerShell):iwr -useb https://raw.githubusercontent.com/AlexsJones/llmfit/main/install.ps1 | iex
• 或通过Cargo安装:cargo install llmfit - 运行:
llmfit—— 立即看到你的硬件详情 + 推荐模型列表
• 按b查看全球用户实测性能榜
• 按H切换硬件预设做对比
• 按Enter选择模型,自动生成对应Ollama/llama.cpp/MLX的完整运行命令
项目信息
Hundreds of models & providers. One command to find what runs on your hardware.
⭐
25.9k
25.9k
Stars
🔀
1.6k
Forks
1.6k
Forks
Rust
📄
MIT
MIT
Rust 编写|GitHub Star 数:25893|MIT 开源协议|GitHub 项目地址
与其在模型海洋里盲目潜水,不如用 llmfit 打开一张精准的本地AI导航图——你的时间,值得花在生成创意上,而不是调试环境上。