你是否也有一块或两块 RTX 3090 显卡,却苦于无法稳定运行 20B 级别的主流大模型?「club-3090」正是为这类硬件条件受限但追求实用性的开发者、技术爱好者和家庭实验室用户量身打造的开源项目——它不是从零造轮子,而是把经过千次实测验证的部署方案、Docker 配置、内存优化补丁和性能基准数据,全部打包成开箱即用的「菜谱」。无论你是想搭建私有 OpenAI 兼容 API,还是为 AI Agent 提供高鲁棒性后端,它都帮你绕过了最坑的编译报错、显存溢出和上下文截断问题。
核心功能
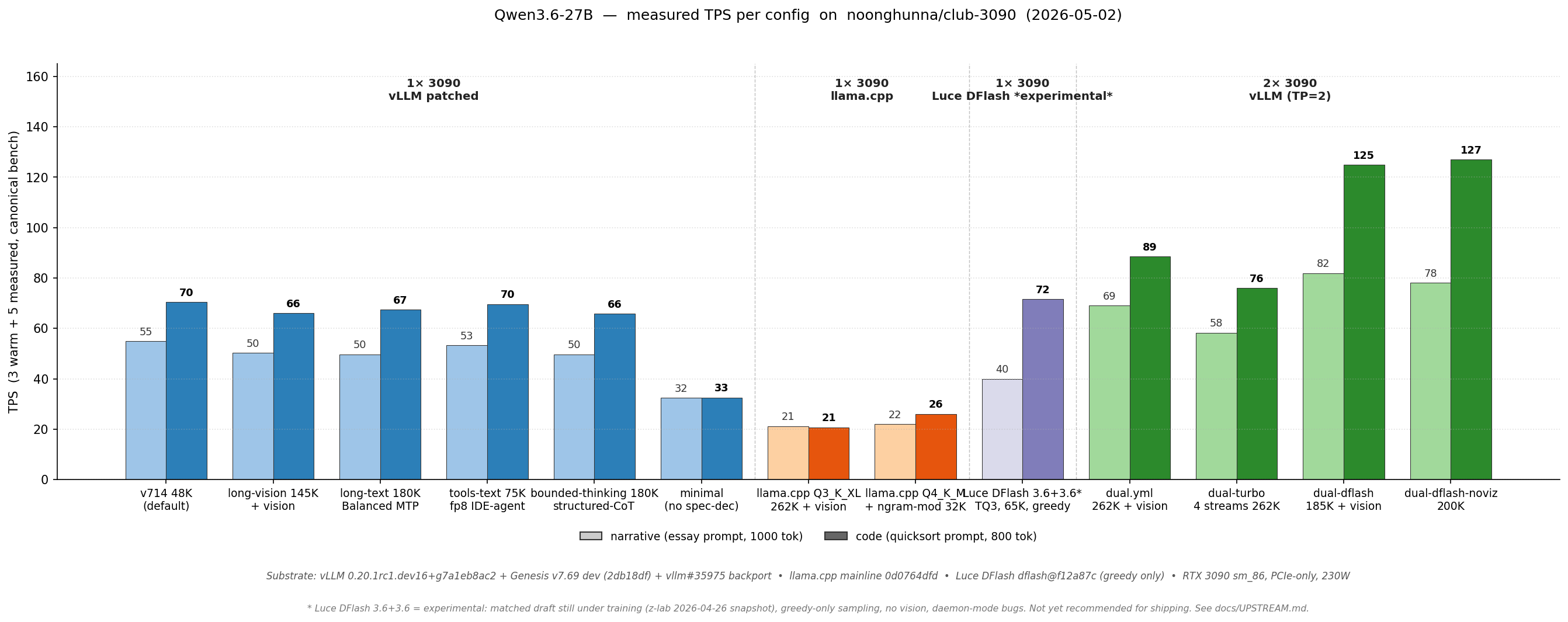
- 双引擎智能选型:提供 vLLM(高吞吐)与 llama.cpp(超长上下文+强稳定性)两种成熟路径,按需切换——vLLM 支持 4 并发流、262K 上下文及完整工具调用能力;llama.cpp 则在单卡上稳跑 262K 上下文,连 90K「针尖测试」都通过,专治真实场景下的 Agent 崩溃。
- 开箱即用的 Docker Compose 部署:所有配置已容器化,执行一条
docker-compose up即可启动标准 OpenAI 兼容 API(默认 localhost:8020),前端、LangChain 或 Ollama 都能无缝对接。 - 首发深度适配 Qwen3.6-27B:针对当前中文最强开源模型之一,提供 1× 和 2× RTX 3090 的完整量化策略、分片方案与启动参数,含 AWQ/GGUF 多格式支持。
- 模型无关架构设计:配置结构清晰分离模型、引擎与硬件层,未来新增 Yi、DeepSeek、Phi-3 等模型只需复用现有模板,无需重写底层逻辑。
- 全链路文档体系:附带详尽的 硬件指南(明确说明 NVLink 非必需)、术语手册(TPS/KV Cache/MTP 全解释)和 引擎对比速查表,新手也能看懂每行参数的意义。
- 持续演进的社区共建机制:项目采用 Apache-2.0 协议,鼓励提交你的 3090 实测配置(如 Llama-3-70B 8-bit 分卡方案),让个人经验变成集体资产。
适合哪些人用
如果你符合以下任一身份,这个项目就是为你而生:个人开发者——想用家里的旧卡搭建私有 AI 后端,不依赖云服务;高校研究者——需要稳定长上下文支持论文实验或教学演示;AI 产品原型工程师——快速验证多模型 Agent 流程,拒绝因显存抖动中断调试;技术博主与极客——乐于折腾但讨厌重复踩坑,追求「改一行参数就能跑通」的确定性体验。注意:它不面向纯小白(需基础 Docker/Linux 操作能力),也不面向企业级集群(暂未支持多机分布式)。
快速上手
以单卡 RTX 3090 运行 Qwen3.6-27B 为例:
- 确保系统已安装 Docker 和 Docker Compose(推荐 v2.20+)
- 克隆项目:
git clone https://github.com/noonghunna/club-3090.git && cd club-3090 - 下载模型权重(如 HuggingFace 的 Qwen3.6-27B-AWQ 格式),放入
models/目录 - 启动 vLLM 方案:
cd docker/vllm && docker-compose up -d(API 自动监听 8020 端口) - 测试调用:
curl http://localhost:8020/v1/chat/completions -H "Content-Type: application/json" -d '{"model":"qwen3.6-27b","messages":[{"role":"user","content":"你好"}]}'
详细步骤、模型下载指引与故障排查见项目 README 快速入门章节。
项目信息
Community recipes for serving LLMs on RTX 3090. Multi-engine (vLLM, llama.cpp, SGLang) and model-agnostic. Currently shipping Qwen3.6-27B configs for
编程语言:Python|GitHub Star 数:468|开源协议:Apache-2.0|GitHub 项目地址
它不承诺「零门槛」,但兑现了「少走弯路」——把 RTX 3090 这张被低估的卡,真正变成你本地大模型开发的可靠生产力引擎。