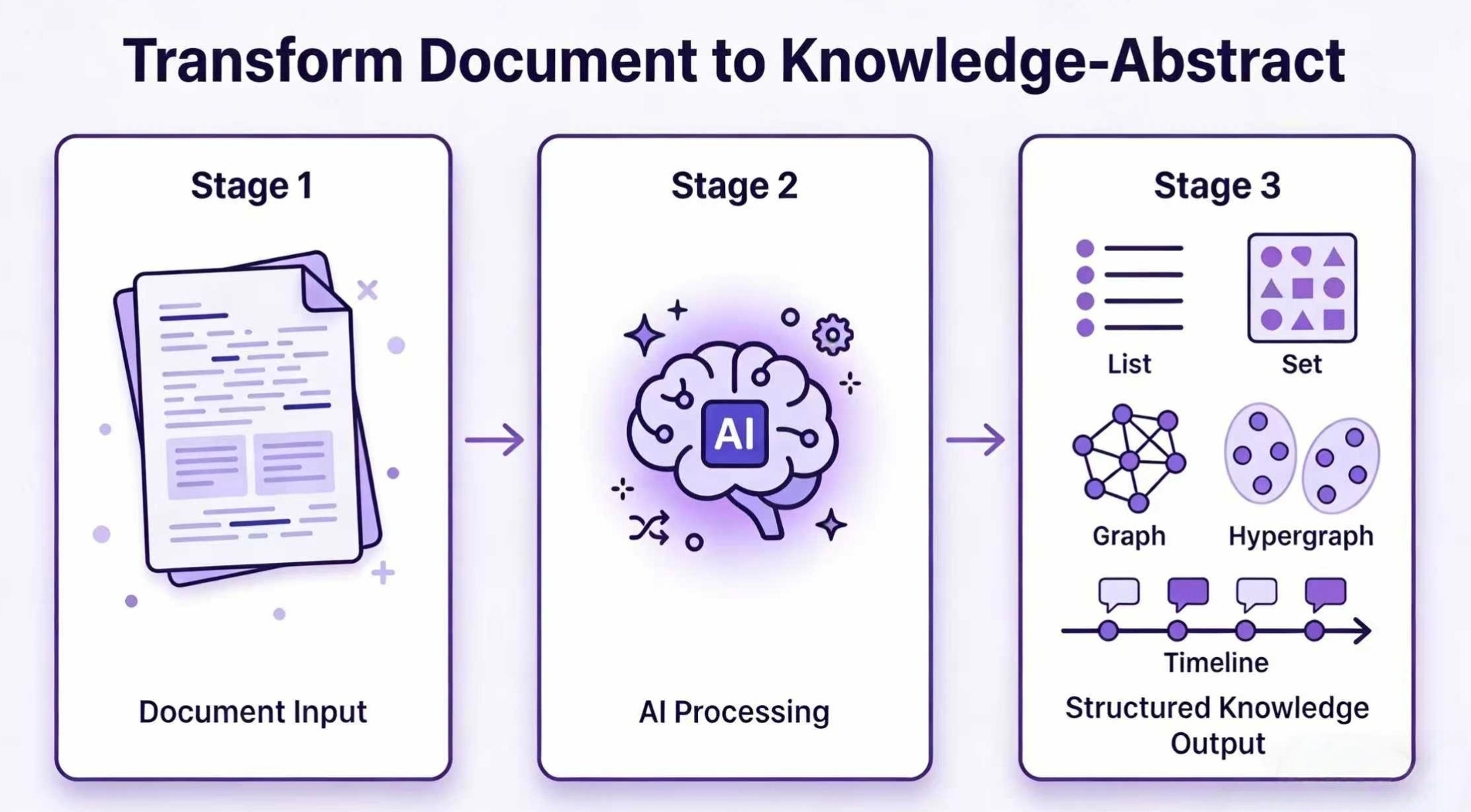
你是否曾面对几十页PDF报告、会议纪要或技术白皮书,一边划线一边发愁“重点在哪?关系怎么理?”——Hyper-Extract 就是为此而生:它不是简单的关键词提取器,而是一个由大语言模型(LLM)驱动的智能知识萃取引擎,只需一条命令,就能把毫无章法的文本自动转化为可查询、可关联、可演化的结构化知识——比如知识图谱、超图、时空事件链等专业表达形式。
核心功能
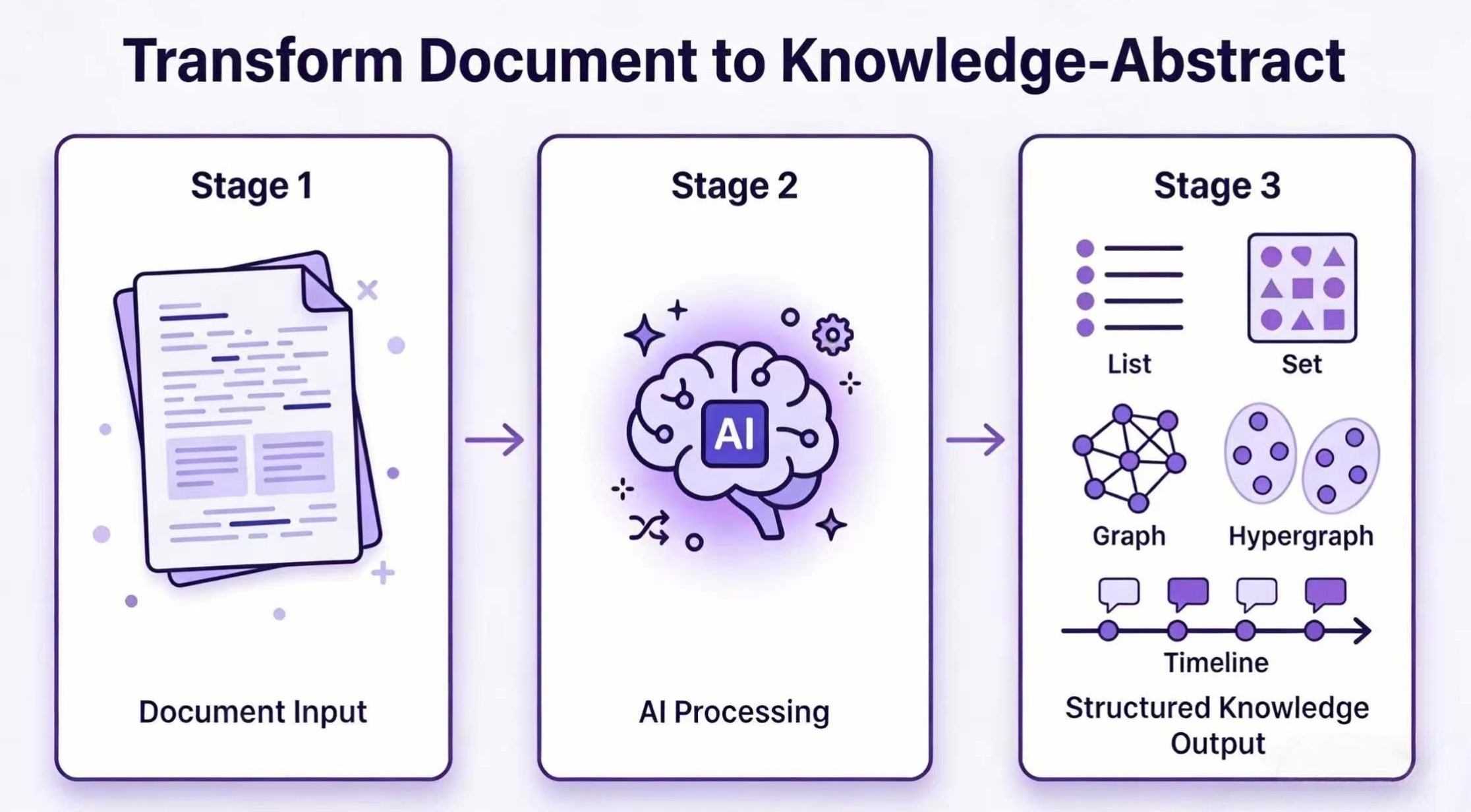
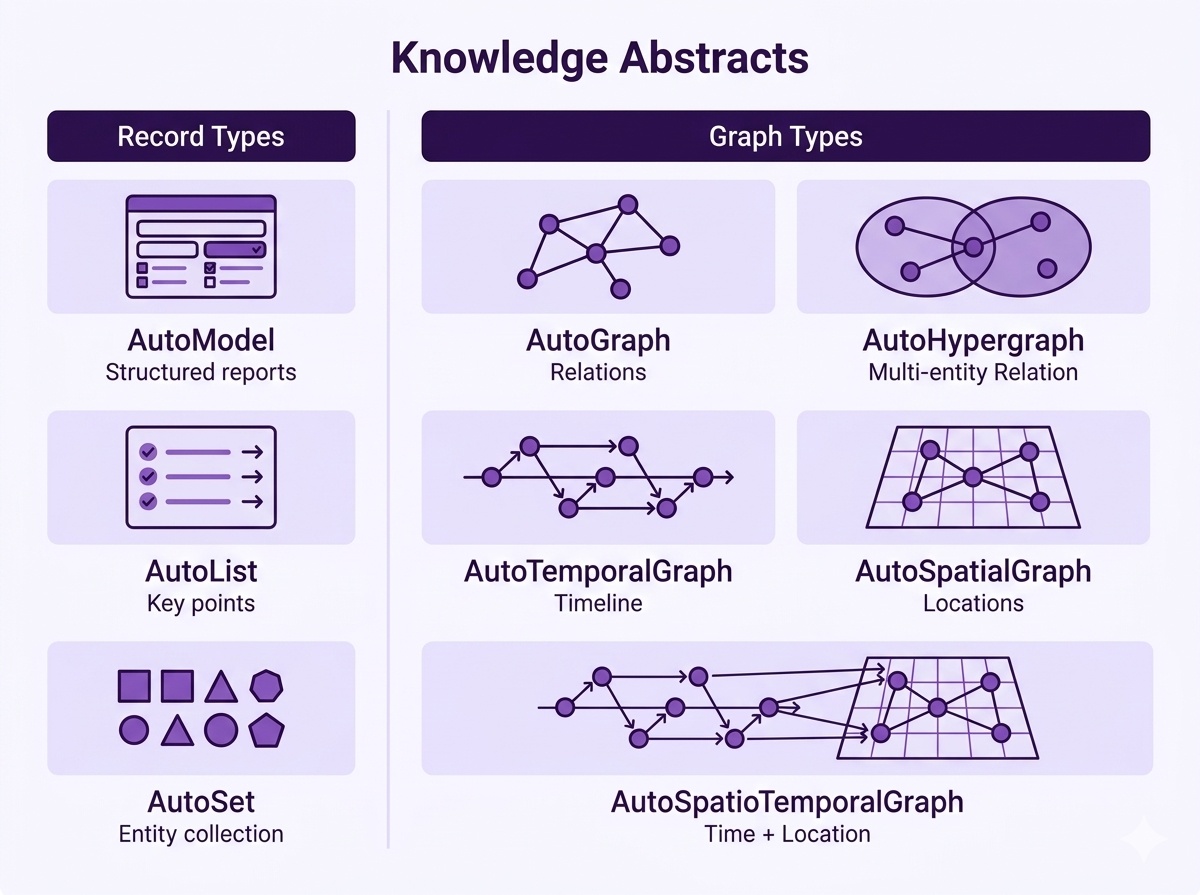
- 一命令生成多模态知识抽象:支持输出标准知识图谱(实体+关系)、超图(多节点协同关系)、时空序列(时间线+地理坐标)、JSON Schema 等多种强类型结构,告别手动画图和手动整理表格。
- 真正理解语义,不止匹配字面:基于微调优化的LLM pipeline,能识别隐含逻辑(如“张三于2023年加入A公司,2024年主导B项目”→自动推导“任职关系”与“项目领导关系”),而非简单正则匹配。
- 开箱即用的CLI体验:无需写代码、不需搭服务,安装后直接运行
hyperextract --file report.pdf --format kg,几秒内拿到结构化结果,适合嵌入日常工作流。 - 面向RAG与知识库建设深度优化:输出结果天然适配向量数据库(如Chroma、Weaviate),支持自动生成元数据、关系索引和上下文摘要,大幅提升检索准确率与问答质量。
- 支持批量处理与增量演化:可对上百份文档并行提取,并自动合并、去重、推理新关系,让知识库随业务持续“生长”,而非静态快照。
- 中文友好,开箱即用:内置针对中文学术/商业文本优化的提示工程与后处理规则,对政策文件、技术文档、产品需求等场景表现稳定可靠。
适合哪些人用
如果你是企业知识管理者,正为散落各处的会议记录、客户反馈、产品文档难以复用而头疼;如果你是RAG应用开发者,厌倦了手工清洗数据、设计schema、调试embedding效果;如果你是研究者或咨询顾问,需要快速从大量文献中抽提概念网络与演化路径;甚至如果你是学生或自学者,想把冗长教材自动转成思维导图式知识图谱——Hyper-Extract 都是你值得放进工具箱的“知识加速器”。
快速上手
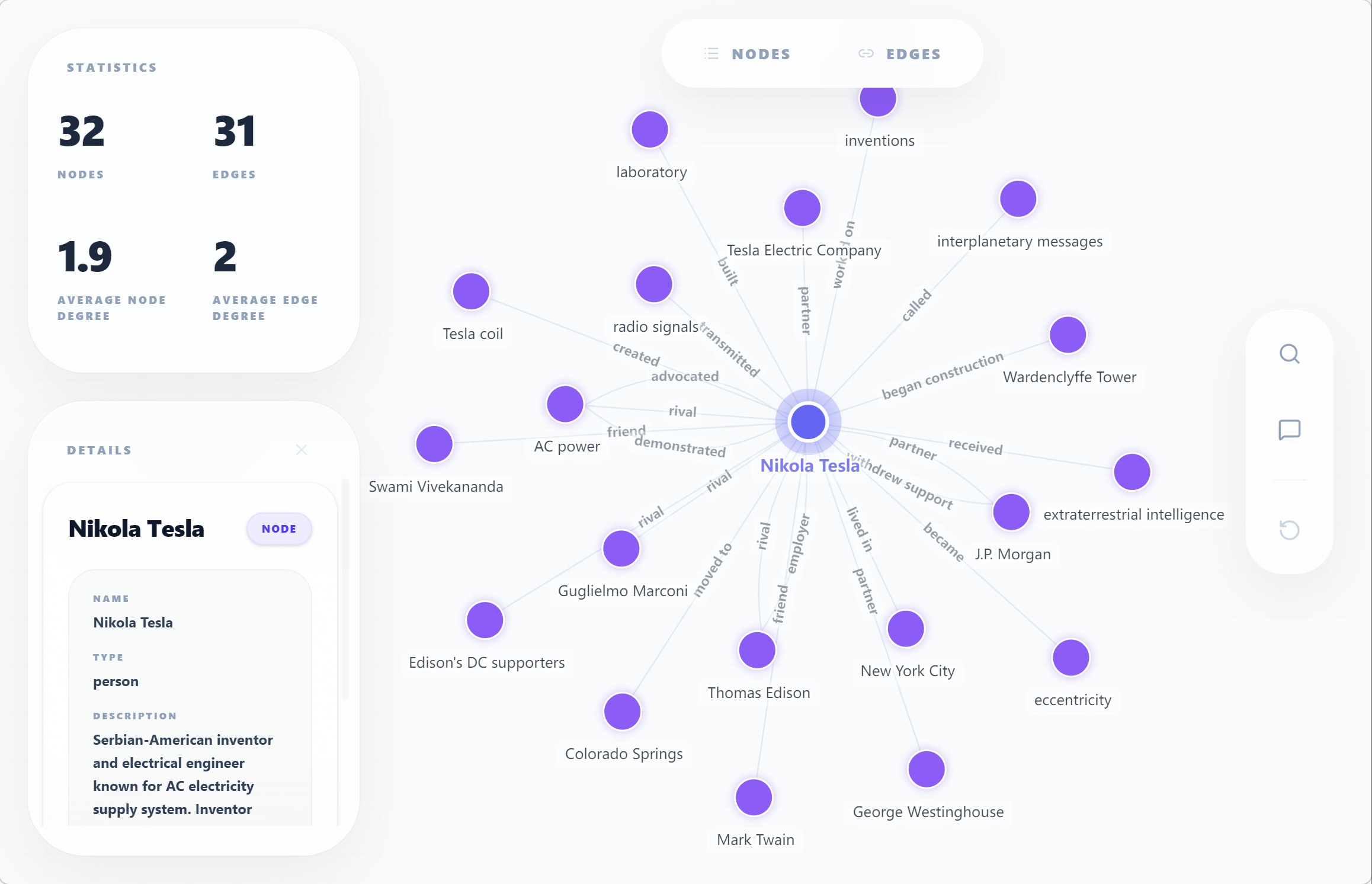
只需两步:
- 安装:打开终端,运行
pip install hyperextract(要求 Python 3.11+,推荐使用虚拟环境); - 使用:例如提取PDF中的知识图谱:
hyperextract --file ./annual_report.pdf --format kg --output ./kg.json;支持输入格式包括TXT、MD、PDF(自动OCR)、DOCX;也可通过--model gpt-4o或本地Ollama模型指定推理引擎。
更多进阶用法(如自定义schema、API集成、Docker部署)详见官方文档(含完整中文指南)。
项目信息
Transform unstructured text into structured knowledge with LLMs. Graphs, hypergraphs, and spatio-temporal extractions — with one command.
⭐
1.7k
今日 +124 stars today
Stars
1.7k
今日 +124 stars today
Stars
🔀
197
Forks
197
Forks
Python
📄
NOASSERTION
NOASSERTION
编程语言:Python|GitHub Star 数:1723|开源协议:Apache 2.0|GitHub 项目地址
让每一份文档都成为可计算、可推理、可传承的知识资产——而不是等待被遗忘的数字废料。