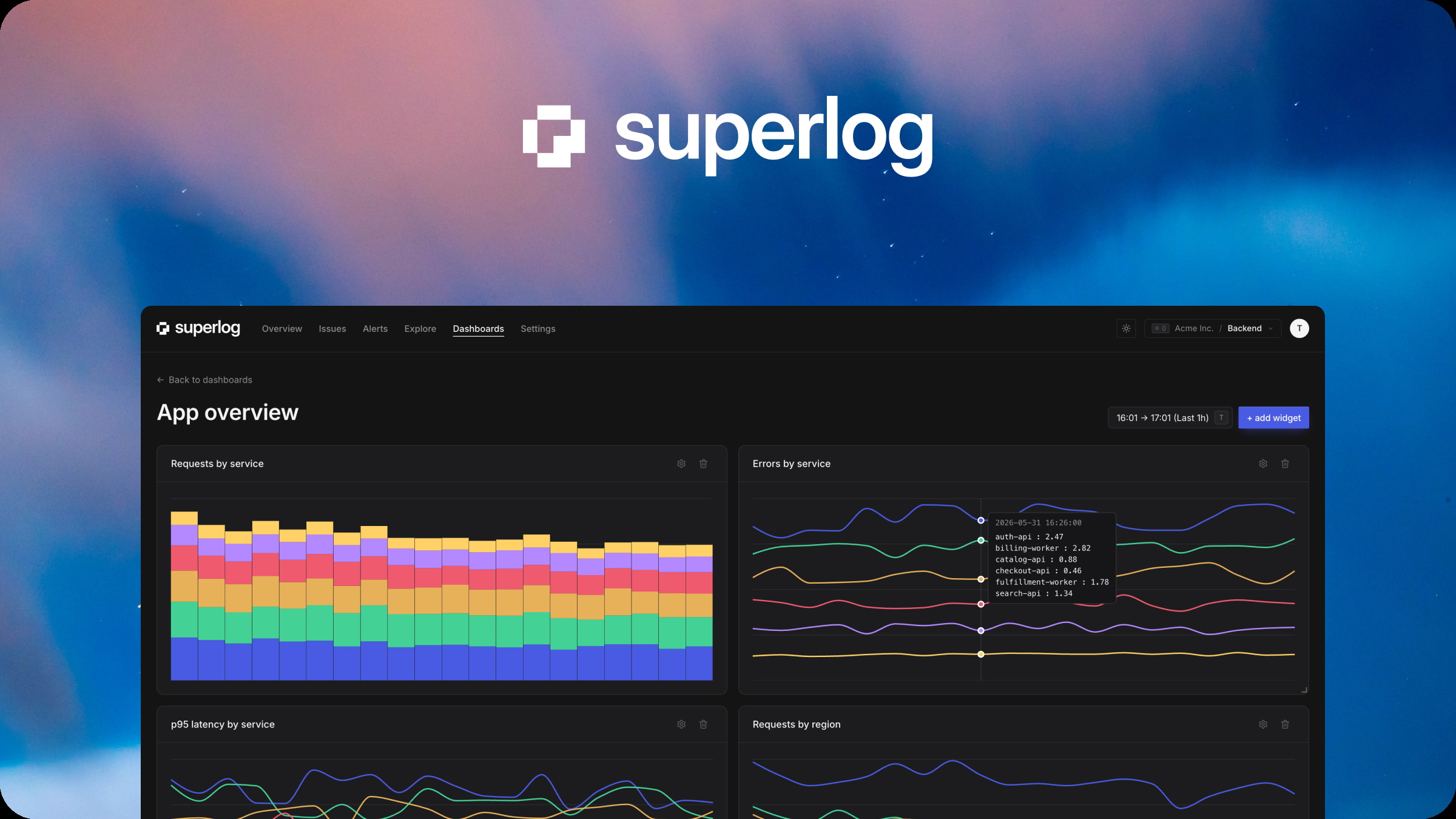
SuperLog 是一个开源的 AI 增强型可观测性(Observability)工具,它不只是帮你“看到”系统哪里出了问题,更能让 AI 代理(Agent)主动分析错误、定位根因,甚至自动生成修复建议或执行预设的修复动作——真正实现从“被动监控”到“主动自愈”的跃迁。它深度兼容 OpenTelemetry 标准,支持全链路日志、指标、追踪数据接入,并通过可插拔的 AI 技能(Skills)模块,让运维和开发团队告别深夜告警疲劳与重复救火。
核心功能
- AI 驱动的异常归因分析:基于 LLM 和长期记忆(Memory),自动关联分散在日志、Trace 和 Metrics 中的线索,一句话指出“为什么订单支付超时?根源是 Redis 连接池耗尽 + 重试策略未降级”
- 自愈式技能引擎(Self-Healing Skills):预置或自定义可执行的修复技能——如自动扩容 Pod、刷新缓存、回滚配置、触发熔断开关,AI 判断后一键执行,无需人工干预
- OpenTelemetry 原生支持:零改造接入现有 OTel Instrumentation,兼容 Jaeger、Prometheus、Loki 等生态组件,轻松复用已有观测数据管道
- 可解释的决策过程:所有 AI 分析和操作都附带清晰推理链(Reasoning Trace),显示“依据哪几条日志、哪个 Span、哪些指标阈值”得出结论,杜绝黑箱操作
- 本地化、可私有部署:100% 开源,支持完全离线运行;敏感数据不出内网,LLM 可对接本地模型(如 Ollama、vLLM)或企业级 API 网关
- 低代码技能编排界面:通过可视化流程图或 YAML 定义 AI 技能逻辑(如“当 CPU >90% 持续5分钟 → 查看对应 Pod 日志 → 若含 OutOfMemoryError → 执行 jvm_heap_reset”),运维也能快速上手
适合哪些人用
如果你是以下角色之一,SuperLog 正在解决你最头疼的痛点:
• DevOps/SRE 工程师:厌倦了写无数条 Prometheus Alert Rule 却仍漏掉复合故障?需要把“告警→查日志→翻文档→试修复”的 45 分钟流程压缩到 90 秒内。
• 后端/全栈开发者:想在本地调试阶段就模拟生产级故障响应,或为微服务内置“智能兜底能力”。
• 中小团队技术负责人:缺乏专职 SRE,但又不敢把核心系统交给黑盒 APM;需要一个透明、可控、能随业务演进的可观测性基座。
• AI Infra 团队:正在探索 LLM 在运维领域的落地场景,需要一个真实、结构化、带反馈闭环的工程化实验平台。
快速上手
只需三步即可启动本地体验版(Docker 环境):
- 克隆仓库:
git clone https://github.com/superloglabs/superlog && cd superlog - 一键启动(含前端、后端、内存数据库、示例 OTel Collector):
docker-compose up -d - 访问 http://localhost:3000,导入示例数据,点击「Run Auto-Heal Demo」立即体验 AI 自诊断全过程
生产部署推荐使用 Helm Chart(官方提供),支持 Kubernetes 集群一键安装,并可灵活对接企业认证、对象存储、外部 LLM 服务及现有 Grafana/Prometheus。
项目信息
TypeScript | 813★ | Apache-2.0 开源协议 | GitHub 项目地址
如果你希望可观测性不再只是“画好看的仪表盘”,而是真正成为系统的免疫系统——看得清、判得准、动得快,SuperLog 就是目前中文社区最值得认真尝试的开源答案。