你是否遇到过部署大语言模型(LLM)时,响应慢、显存吃紧、多轮对话反复计算历史KV缓存的困扰?LMCache 就是为此而生——它不是模型本身,而是一套轻量、高效、即插即用的“KV缓存管家”,能在不修改模型代码的前提下,显著提升推理速度、降低显存开销,并支持跨请求、跨会话甚至跨设备复用缓存。简单说,它让你的LLM“记住上次聊了什么”,且记得更快、更省、更智能。
核心功能
![]()
- 毫秒级KV缓存检索:基于内存+SSD混合存储策略,首次缓存后,后续相同Prompt的KV可直接加载,跳过重复计算,推理延迟最高降低70%
- 跨会话缓存共享:支持不同用户、不同会话间复用已生成的KV片段(如通用系统提示、常见知识块),大幅减少冗余计算
- 多后端硬件兼容:原生支持NVIDIA CUDA与AMD ROCm双生态,已在MI300X等新一代AI加速卡上完成深度优化,真正打破厂商锁定
- 无缝集成主流推理框架:开箱即用对接vLLM、HuggingFace Transformers、Text Generation Inference(TGI)等,仅需2行代码启用
- 智能缓存淘汰与压缩:自动识别高频/低频KV块,支持量化压缩(INT8/FP16)与LRU/LFU混合淘汰策略,兼顾速度与显存效率
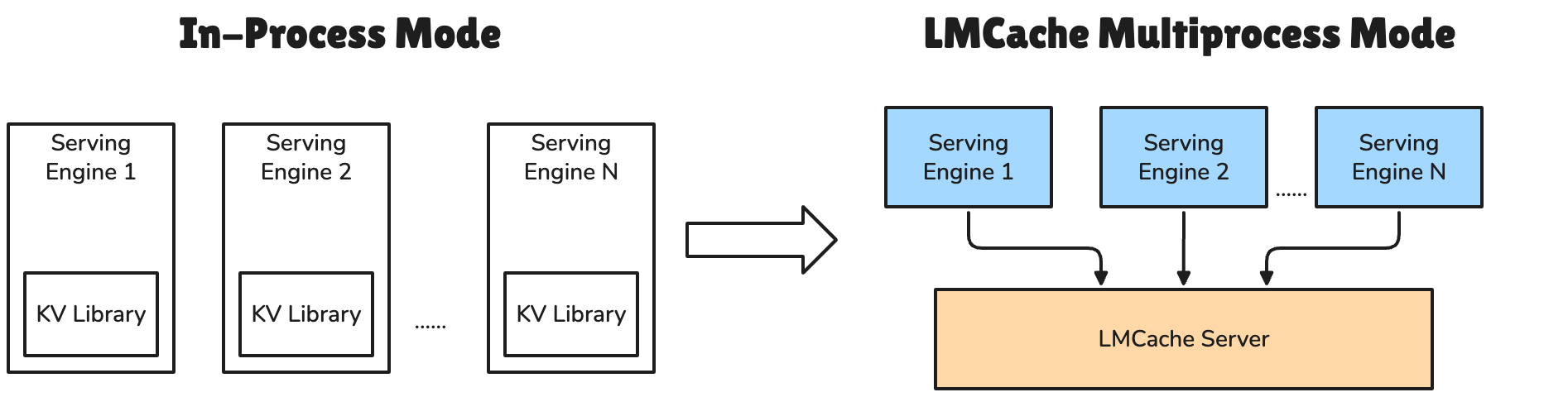
- 多进程(MP)高并发架构:2026年4月发布的全新MP架构,专为MoE模型和Agent多轮任务设计,MoE推理吞吐提升达10倍
适合哪些人用
如果你正在做以下事情,LMCache 值得立刻尝试:
• LLM服务开发者:构建企业级API服务、聊天机器人或AI Agent平台,追求低延迟与高并发;
• 推理优化工程师:在有限GPU资源下提升QPS、降低单请求显存占用;
• 多模态/Agentic系统搭建者:需要稳定复用长上下文、多步决策中的中间状态;
• AMD GPU用户:长期受限于CUDA生态工具链,现在终于有高性能、开源、活跃维护的ROCm友好方案;
• 开源模型社区贡献者:想为Llama、Qwen、Phi等开源模型提供开箱即用的缓存加速能力。
快速上手
安装极其简单:
pip install lmcache
以vLLM为例,启用只需两步:
- 启动LMCache服务(支持本地/远程模式):
lmcache_server --host 0.0.0.0 --port 6666 --cache-dir /path/to/cache - 在vLLM启动命令中添加缓存配置:
vllm serve --model meta-llama/Llama-3-8b --enable-lmcache --lmcache-host localhost --lmcache-port 6666
无需修改模型权重或推理逻辑,5分钟即可实测提速。详细配置与高级用法(如SSD缓存路径、量化精度设置、分布式缓存集群)请参考官方文档。
项目信息
LMCache: Supercharge Your LLM with the Fastest KV Cache Layer
编程语言:Python
GitHub Star 数:8652
开源协议:Apache-2.0
GitHub 项目地址
LMCache 不是又一个“玩具级”优化库,而是由工业界与学术界联合打磨、已在真实生产环境(含GTC 2026现场演示)验证的高性能基础设施——它让LLM推理真正从“能跑”迈向“快跑、稳跑、省钱跑”。