你是否厌倦了传统 RAG(检索增强生成)中繁琐的文档分块、向量化、向量库维护和语义漂移?PageIndex 是一个颠覆性的开源工具——它不依赖任何向量数据库,也不做机械切片,而是让大模型通过多步推理“理解文档结构与语义逻辑”,再精准定位答案所在页、段或章节。它把 RAG 从“关键词匹配+向量相似度”的统计游戏,升级为“先理解、再推理、后检索”的类人认知过程。
核心功能
- 零向量库依赖:无需 Chroma、Qdrant 或 FAISS,彻底摆脱向量嵌入、索引构建与定期更新的运维负担
- 原生文档感知检索:自动识别 PDF/Word/Markdown 等格式的标题层级、列表、表格、代码块等结构信息,实现“按逻辑单元”而非“按固定长度”检索
- 推理驱动的上下文定位:调用 LLM 进行多跳推理(如:“先找方法论章节 → 再定位实验设计子节 → 最后提取参数表格”),支持复杂查询意图分解
- 无损上下文保留:直接返回原始文档中的完整段落或页面截图(含格式),避免 chunking 导致的关键信息截断或语义断裂
- 开箱即用的 Agentic 工作流:内置可组合的智能体(Agent)模板,支持自主规划检索路径、验证结果一致性、迭代优化查询策略
- 全栈可扩展接口:提供标准 MCP(Model Context Protocol)协议支持、RESTful API 和 Python SDK,轻松集成进现有 AI 应用或知识管理系统
适合哪些人用
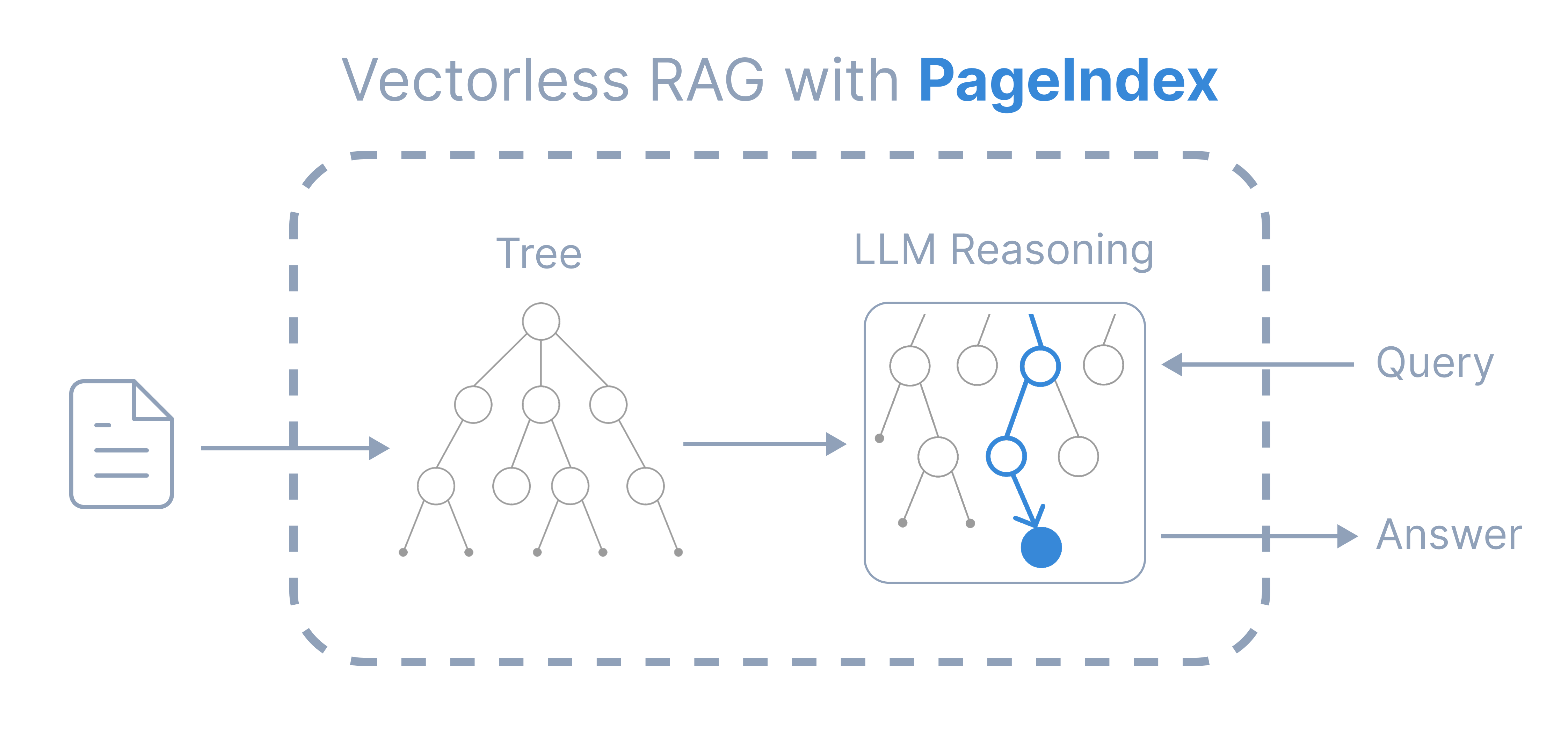
PageIndex 不是给算法工程师调参用的底层库,而是为真正需要“用好文档”的一线实践者打造的生产力工具:企业知识库搭建者、技术文档工程师、法律/金融/医疗等专业领域的智能助手开发者、高校科研团队的知识管理负责人,以及所有受困于“RAG 总是答非所问、找不到重点、改个文档就要重跑整个 pipeline”的 AI 应用落地者。如果你希望用户问一句“上季度合规审计报告里第三部分提到的整改时限是多久?”,系统就能准确翻到对应 PDF 的第 17 页并高亮原文——那 PageIndex 正是为你而生。
快速上手
只需三步,5 分钟内体验“有思考的检索”:
- 安装:运行
pip install pageindex(Python 3.9+) - 加载文档:支持本地路径或 URL,例如
doc = pageindex.load("manual.pdf") - 发起推理检索:调用
doc.query("如何配置双因素认证?", strategy="reasoning"),即可获得带推理链的精准结果
进阶用户可一键启动本地服务:pageindex serve --port 8000,随后通过 Web UI(chat.pageindex.ai)或 API 直接交互。所有示例代码(含 Agentic RAG 演示)均在项目 /examples 目录下开源可复用。
项目信息
📑 PageIndex: Document Index for Vectorless, Reasoning-based RAG
29.3k
今日 +953 stars today
Stars
2.5k
Forks
Python
MIT
编程语言:Python|GitHub Star 数:29,260|开源协议:MIT|GitHub 项目地址
PageIndex 用极简架构实现了 RAG 范式的认知跃迁——它证明:真正的智能检索,不靠更多算力堆砌向量,而靠更清晰的推理设计。