你是否遇到过:和大模型聊天时,明明问题很简单,却要等好几秒才看到第一个字?这背后是传统自回归解码的“逐词生成”瓶颈。DFlash 是一个开源的轻量级加速工具,它不改变你的主力大模型,而是悄悄训练一个极小的“草稿助手”(Block Diffusion 模型),提前并行猜出接下来的多个词,再由主模型快速验证——大幅缩短等待时间,实测提速 40%~100%,且几乎不牺牲回答质量。
核心功能
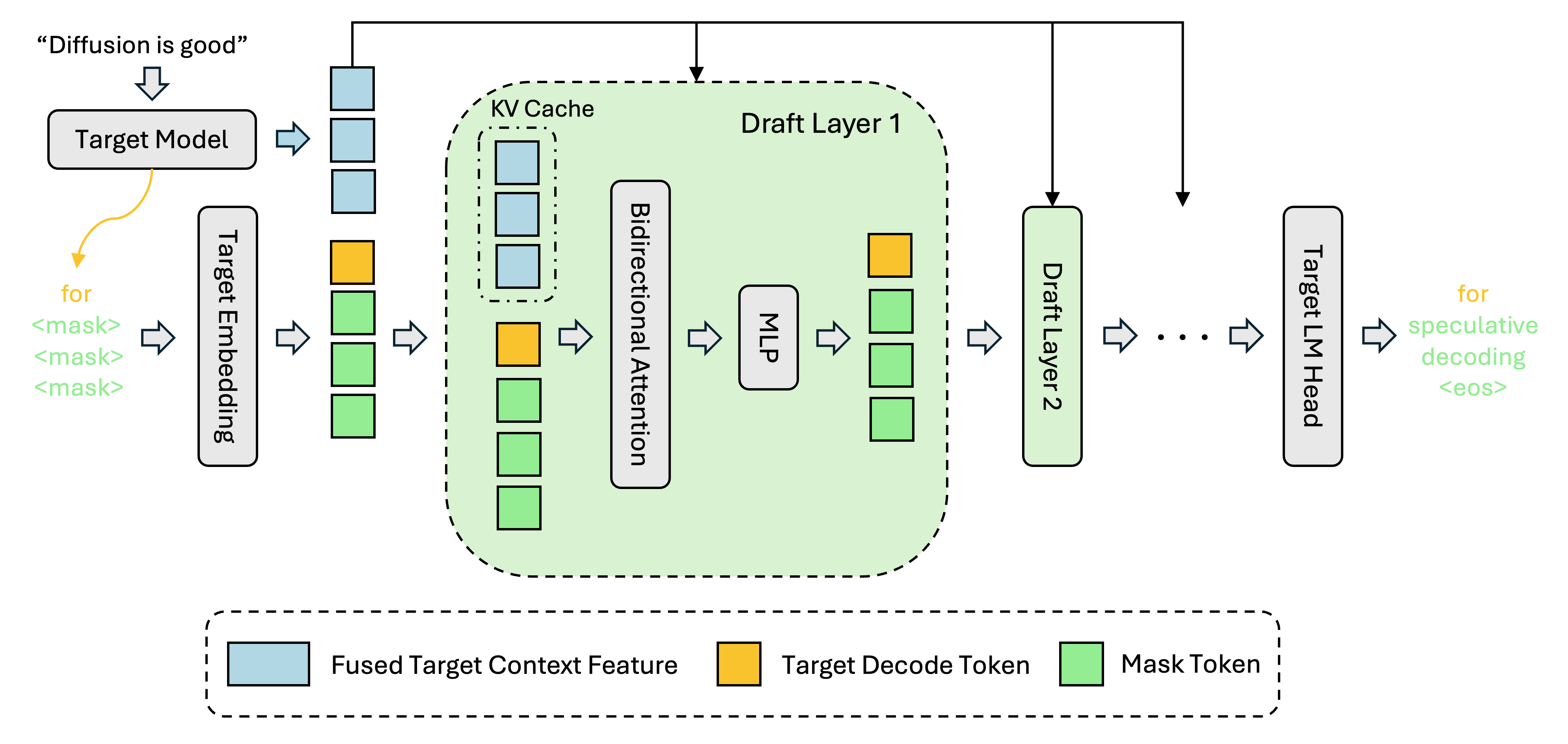
- 闪电式推测解码:基于创新的 Block Diffusion 架构,一次性生成多个候选 token 块,而非单个 token,显著提升并行效率
- 零侵入兼容主流模型:无需修改原模型结构或权重,已为 Gemma-4、Qwen3.5/3.6、Kimi-K2.5、MiniMax-M2.5 等热门中文/多语言大模型提供即用型 DFlash 草稿模型
- 超低资源开销:草稿模型参数量仅为主模型的 1%~3%,可在单张消费级显卡(如 RTX 4090)上流畅运行,不增加部署负担
- 开箱即用的 Hugging Face 集成:所有预训练 DFlash 模型均已上传至 Hugging Face Model Hub,支持 transformers + vLLM + llama.cpp 多后端无缝调用
- 支持动态草案长度控制:可根据输入复杂度智能调整每次预测的 token 数量,在速度与准确率间灵活平衡
- 完整推理链可视化调试:内置日志与统计模块,可清晰查看“猜对多少”“重采样几次”,便于开发者优化部署策略
适合哪些人用
如果你是以下角色,DFlash 就是为你准备的“推理加速器”:AI 应用开发者(想降低 API 延迟、提升用户对话流畅度)、大模型服务运维工程师(需在有限 GPU 资源下支撑更高并发)、高校研究者(探索高效推理新范式,或复现论文结果)、以及关注国产大模型生态的技术爱好者——尤其推荐搭配 Qwen3.5/3.6、Kimi-K2.5 等国内头部模型使用,中文场景优化更到位。
快速上手
只需三步,5 分钟接入现有流程:
- 安装依赖:
pip install dflash transformers accelerate - 加载预训练草稿模型(以 Qwen3.5-9B 为例):
from dflash import DFlashDraftModel
draft_model = DFlashDraftModel.from_pretrained("z-lab/Qwen3.5-9B-DFlash") - 与主流推理框架集成(如 vLLM):
启动时添加参数--speculative-model z-lab/Qwen3.5-9B-DFlash --num-speculative-tokens 5,即可开启加速模式
详细教程、性能对比表格及 Jupyter 示例见项目官方 Blog:z-lab.ai/projects/dflash/
项目信息
DFlash: Block Diffusion for Flash Speculative Decoding
编程语言:Python|GitHub Star 数:3227|开源协议:MIT|GitHub 项目地址
如果你正在为大模型“卡顿”发愁,又不想折腾复杂编译或昂贵硬件——DFlash 这台小巧聪明的“预测草稿机”,值得你立刻试试看。