
DeepEP 是由深度求索(DeepSeek)开源的一款高性能 GPU 通信库,专为混合专家(Mixture-of-Experts, MoE)模型的专家并行(Expert Parallelism, EP)场景深度优化。它直击大模型训练中的一大瓶颈——跨 GPU 专家数据调度延迟高、带宽利用率低的问题,用定制化 CUDA 内核替代通用通信原语,在 NVLink 与 RDMA 网络混合架构下实现超低延迟、超高吞吐的专家数据分发与聚合。无论是 DeepSeek-V3 这类千亿级 MoE 模型的预训练,还是实时性要求严苛的推理生成,DeepEP 都能显著缩短通信开销,把更多算力真正留给计算。
核心功能
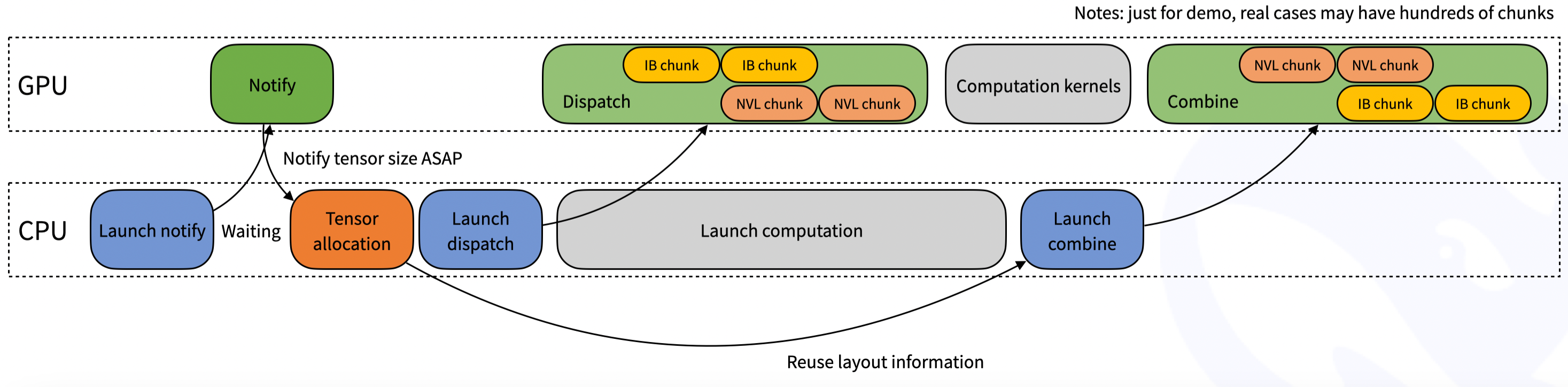
- 极致优化的 All-to-All 内核:提供业界领先的 MoE “Dispatch(分发)”与“Combine(聚合)”GPU 原语,支持 FP8 低精度通信,在 H800 + CX7 InfiniBand 环境下实测吞吐逼近硬件理论上限
- 异构域带宽协同转发:首创适配 DeepSeek-V3 论文提出的“组限门控(group-limited gating)”算法,可高效完成 NVLink 域(高速芯片内互联)到 RDMA 域(跨节点远程互联)的非对称带宽数据转发
- 双模推理优化支持:既含高吞吐“预填充(prefill)”内核,也提供纯 RDMA 驱动的超低延迟“解码(decoding)”内核,满足生成式 AI 对不同阶段的时延敏感性需求
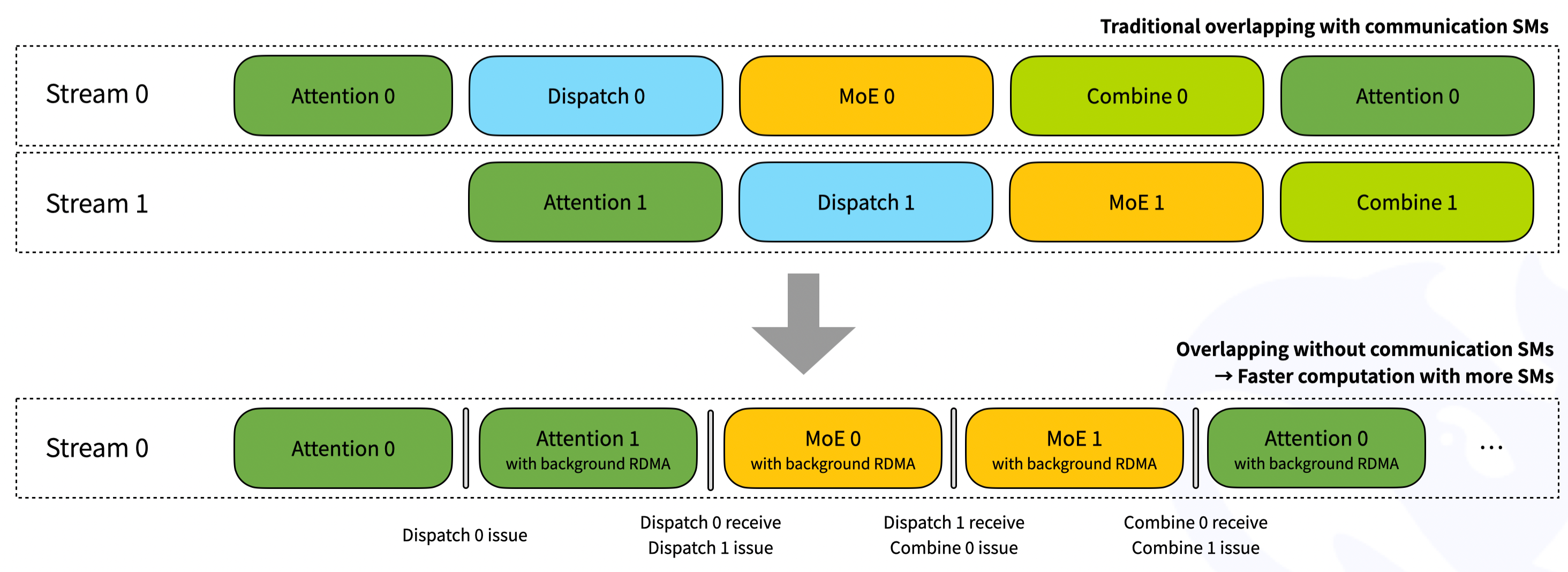
- 零资源占用的通信-计算重叠:通过创新的 Hook 机制实现通信与计算完全异步,不抢占任何 Streaming Multiprocessor(SM)资源,GPU 利用率拉满
- 细粒度硬件控制能力:支持动态调节 SM 使用数量,便于在多任务混部或资源受限场景下灵活平衡性能与稳定性
- 生产就绪设计:MIT 协议开源,接口简洁,已深度集成于 DeepSeek 自研训练框架,并经大规模预训练验证
适合哪些人用
如果你是以下角色之一,DeepEP 将成为你构建/优化 MoE 大模型的关键基础设施:AI 框架开发者(如 PyTorch / Megatron-LM / DeepSpeed 扩展维护者)、大模型训练工程师(尤其在千卡集群上训练 MoE 模型)、高性能计算(HPC)系统调优专家、以及致力于降低推理首字延迟(Time-to-First-Token)的 LLM 服务部署工程师。普通用户无需直接使用,但所有基于 DeepSeek-V3 或类似 MoE 架构的大模型应用,其底层性能提升都可能受益于 DeepEP。
快速上手
DeepEP 以 C++/CUDA 编写,提供 Python 绑定接口,兼容主流 PyTorch 版本。安装只需三步:
1. 确保环境已安装 CUDA 12.1+、PyTorch 2.3+ 及对应 cuDNN;
2. 克隆仓库并编译:git clone https://github.com/deepseek-ai/DeepEP && cd DeepEP && pip install -v --no-cache-dir --disable-pip-version-check .;
3. 在 MoE 模块中替换原有 all-to-all 调用,例如使用 deep_ep.dispatch() 和 deep_ep.combine() 接口。项目 README 提供完整示例与性能对比脚本,5 分钟即可跑通基准测试。
项目信息
DeepEP: an efficient expert-parallel communication library
9.4k
今日 +52 stars today
Stars
1.2k
Forks
Cuda
MIT
编程语言:CUDA|Star 数:9391|开源协议:MIT|GitHub 项目地址
这是来自中国顶尖 AI 研究团队的硬核基础设施级开源成果,虽托管于 GitHub,但其设计理念与工程实践高度契合国产智算中心多层级互联架构,是中文技术社区值得重点关注的大模型底层优化标杆项目。
如果你正在为 MoE 模型的通信墙头疼,DeepEP 就是那个帮你把“等数据”时间砍掉一半的利器。












