MediaCrawler 是一款专为中文用户打造的开源多平台内容采集工具,能自动抓取小红书笔记、抖音视频、快手短片、B站UP主投稿、微博热搜帖、百度贴吧热帖、知乎问答等主流平台的正文内容及全部评论。它不依赖官方API,而是通过模拟真实用户行为实现高效、稳定的数据获取,特别适合做舆情分析、竞品调研、内容趋势研究和学术数据采集。
核心功能
- 跨平台全覆盖:支持小红书(笔记+评论)、抖音(视频+评论)、快手(视频+评论)、Bilibili(视频+弹幕/评论)、微博(帖子+转发/评论)、百度贴吧(主题帖+楼层回复)、知乎(问题+回答+点赞数)等10+国内主流平台
- 结构化数据导出:所有采集结果自动保存为 Excel(.xlsx)或 CSV 格式,包含发布时间、作者ID、点赞数、评论内容、用户昵称、IP属地(部分平台可解析)等关键字段
- 智能登录与反反爬适配:内置 Cookie 自动更新、滑块验证码识别(需配合第三方服务)、请求频率控制、User-Agent 轮换等策略,大幅提升长期运行稳定性
- 可视化配置界面:提供 Web 管理后台(Flask + Vue),无需写代码即可添加任务、查看进度、下载结果,新手也能快速上手
- 关键词+账号双模式采集:既可按「#穿搭」「AI绘画」等话题关键词批量抓取,也可定向监控指定博主/UP主/大V的全部动态,满足不同研究场景
- 本地化部署 & 隐私可控:所有数据全程本地存储,不上传服务器,完全规避云端爬虫服务的数据泄露风险,符合企业级合规要求
适合哪些人用

这款工具尤其适合:新媒体运营人员——实时追踪竞品内容表现与用户反馈;市场研究人员——批量采集行业讨论热度,生成舆情报告;高校师生与社科研究者——获取真实社交语料用于语言学、传播学、社会学实证分析;独立开发者与技术爱好者——学习现代爬虫架构设计、JS逆向与动态渲染处理技巧;以及需要低成本构建自有内容数据库的中小团队。注意:严禁用于非法采集、恶意刷量、侵犯隐私或商业兜售数据。
快速上手
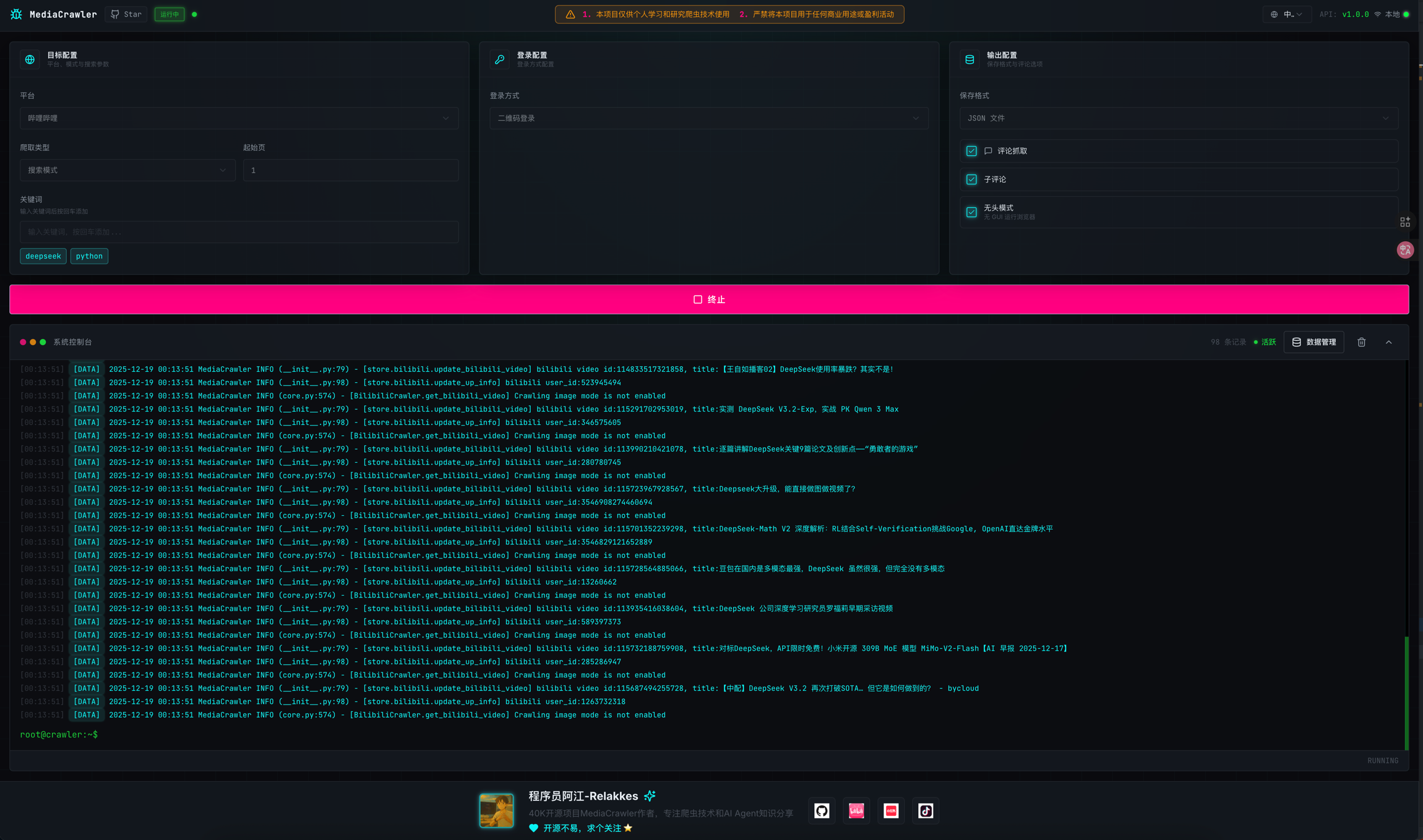
![]()
只需三步即可开始采集:
① 安装 Python 3.9+ 环境,运行 pip install -r requirements.txt 安装依赖;
② 在项目根目录执行 python main.py 启动服务,浏览器访问 http://localhost:5000 进入图形界面;
③ 登录目标平台账号(如小红书/抖音),复制 Cookie 填入对应平台配置页,设置关键词或账号ID,点击「创建任务」即可自动运行。首次使用建议先阅读项目 Wiki 中的《防封指南》与《常见问题排查手册》。
项目信息
小红书笔记 | 评论爬虫、抖音视频 | 评论爬虫、快手视频 | 评论爬虫、B 站视频 | 评论爬虫、微博帖子 | 评论爬虫、百度贴吧帖子 | 百度贴吧评论回复爬虫 | 知乎问答文章|评论爬虫
53.5k
今日 +673 stars today
Stars
11.0k
Forks
Python
NOASSERTION
编程语言:Python|GitHub Star 数:53501|开源协议:NOASSERTION(请务必自行评估法律风险)|GitHub 项目地址
如果你正在为“找不到真实用户评论”“手动复制效率太低”“想对比多个平台内容生态”而发愁,MediaCrawler 就是那个帮你省下80%重复劳动的开源利器。