你是否试过用本地运行的8B小模型(比如Ministral-3或Phi-4)构建多步AI助手,结果它总在关键环节“掉链子”:工具调用参数解析失败、循环步骤跳步、上下文爆显存、或反复犯同一错误?Forge正是为此而生——它不是另一个LLM推理服务器,而是一层轻量却强大的“可靠性中间件”,专为自托管环境下的智能体(Agent)工作流设计,把原本不稳定的本地模型,变成可信赖、可编排、可量产的AI协作者。
核心功能
- 智能守卫栏(Guardrails):自动识别并修复工具调用中的JSON解析错误、参数缺失或格式错乱;通过“重试提示引导(retry nudges)”温和纠正模型,而非粗暴报错重来。
- 多步流程强管控:支持定义清晰的步骤序列(step enforcement),防止模型跳步、重复执行或擅自终止,确保复杂任务(如“查天气→订机票→生成行程单”)严格按逻辑推进。
- VRAM感知型上下文管理:动态监控GPU显存占用,在上下文膨胀时自动启用分层压缩(tiered compaction)——保留关键指令与最新交互,安全裁剪历史冗余,避免OOM崩溃。
- 共享GPU资源调度器(SlotWorker):允许多个智能体(如客服Agent、数据分析Agent、文档总结Agent)排队复用同一块GPU卡;支持优先级抢占与无缝上下文挂起/恢复,大幅提升硬件利用率。
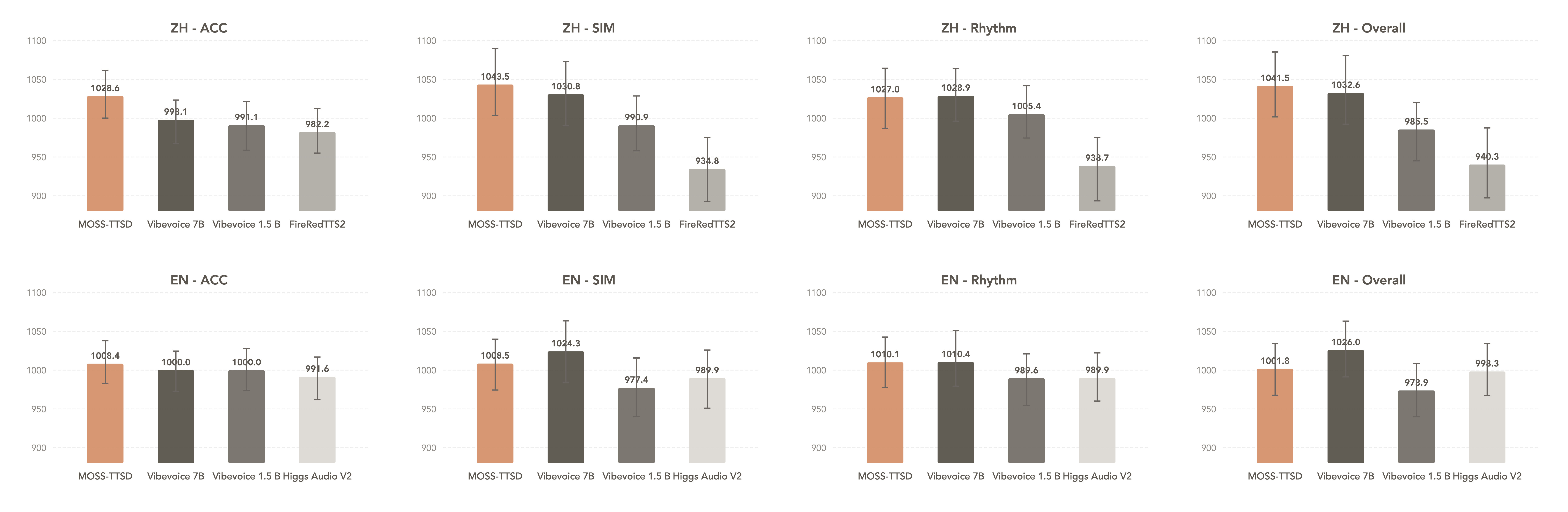
- 开箱即用的评估体系:内置26个真实场景测试套件(含高难度“硬核挑战组”),一键验证你的本地模型+Forge配置在多步任务中的实际可靠性(当前最优配置达86.5%综合通过率)。
- 全后端友好集成:原生支持Ollama、llama.cpp(含llamafile)、LlamaServer等主流本地推理服务,无需修改模型或服务端,仅通过Python客户端即可注入可靠性能力。
适合哪些人用
如果你是以下角色之一,Forge值得立刻加入技术栈:
• 本地AI应用开发者:正在基于Ollama或llama.cpp构建个人知识库、自动化办公助手、私有客服机器人等,需要模型“说到做到”;
• 边缘/私有化部署工程师:受限于GPU资源(如单张RTX 4090),需让多个轻量Agent共享算力并稳定运行;
• AI产品原型设计师:希望快速验证多步骤智能体流程(如“分析日志→定位异常→生成修复建议→提交PR”),而非耗费数周打磨容错逻辑;
• 教育与研究者:探索工具调用、思维链鲁棒性、上下文压缩等前沿课题,Forge提供了可调试、可扩展的参考实现。
快速上手
只需三步,5分钟接入现有项目:
- 安装:
pip install forge-guardrails(支持Python 3.12+) - 定义工具与工作流:用标准Python函数声明工具(如
@tool装饰器),再用WorkflowRunner串联步骤; - 连接本地模型服务:指定Ollama模型名(
"ministral:8b")或llama.cpp服务地址,启动运行——所有系统提示、上下文管理、重试逻辑、显存调控均由Forge后台静默完成。
官方提供完整示例(天气查询+地图导航+行程规划三步工作流)和Jupyter Notebook教程,GitHub仓库的/examples目录即开即用。
项目信息
antoinezambelli/forge
GitHub
A Python framework for self-hosted LLM tool-calling and multi-step agentic workflows
1.4k
今日 +449 stars today
Stars
75
Forks
Python
MIT
编程语言:Python|Star 数:1434|开源协议:MIT|GitHub 项目地址
Forge不是试图造一个更大的模型,而是教会小模型“好好干活”——在资源受限的现实世界里,这才是让AI真正落地的关键一步。