你是否好奇ChatGPT这类大模型到底是怎么“炼”出来的?又是否苦于没有算力、不懂分布式训练而止步于调用API?FareedKhan-dev/train-llm-from-scratch 项目,用最朴实的PyTorch代码和Jupyter Notebook,带你从下载数据、实现Transformer、到完成端到端训练——全程无需多卡,一块消费级GPU(如RTX 3090/4090)即可跑通!它不是黑盒封装,而是一份可读、可调试、可复现的「LLM训练实践手册」。
核心功能

- 纯手工实现Transformer架构:完全基于《Attention Is All You Need》论文,逐行实现嵌入层、多头注意力、前馈网络、LayerNorm与残差连接,无任何高级框架魔改
- 端到端训练流水线:覆盖数据下载(含清洗脚本)、分词(Byte-Pair Encoding)、数据加载、训练循环、学习率调度、检查点保存与恢复全流程
- 轻量级亿级参数模型支持:默认提供1300万参数模型配置(适合单卡),同时开放扩展接口,可平滑升级至上亿参数(需调整batch size与梯度累积)
- 开箱即用的文本生成能力:训练完成后直接调用generate()函数,输入提示词即可输出连贯文本,支持top-k、temperature等常用采样策略
- 极简依赖 & 清晰注释:仅依赖PyTorch、tqdm、numpy等基础库;每个Notebook单元格均附带中文注释与原理说明,新手友好度拉满
- MIT协议开源,鼓励二次开发:代码结构模块化,便于替换Tokenizer、修改模型宽度/深度、接入LoRA微调或切换为FlashAttention加速
适合哪些人用
✅ AI初学者:想真正理解Transformer内部机制,而非只调用Hugging Face pipeline;
✅ 高校学生与研究者:需要可复现的基线模型做对比实验,或用于课程设计、毕业课题;
✅ 工程师与技术博主:希望快速搭建私有小模型服务(如企业知识库问答、内部文案辅助),避免依赖闭源API;
✅ 硬件受限开发者:仅有单张24G显存GPU,仍渴望亲手训练一个“能说话”的模型——这个项目就是为你设计的。
快速上手
只需三步,5分钟启动训练:
- 克隆项目:
git clone https://github.com/FareedKhan-dev/train-llm-from-scratch.git - 安装依赖:
pip install torch tqdm numpy datasets transformers(推荐Python 3.9+) - 运行主Notebook:
jupyter notebook train_llm_from_scratch.ipynb,按顺序执行各章节——从数据准备→模型定义→训练→生成,每步均有详细说明与预期输出提示
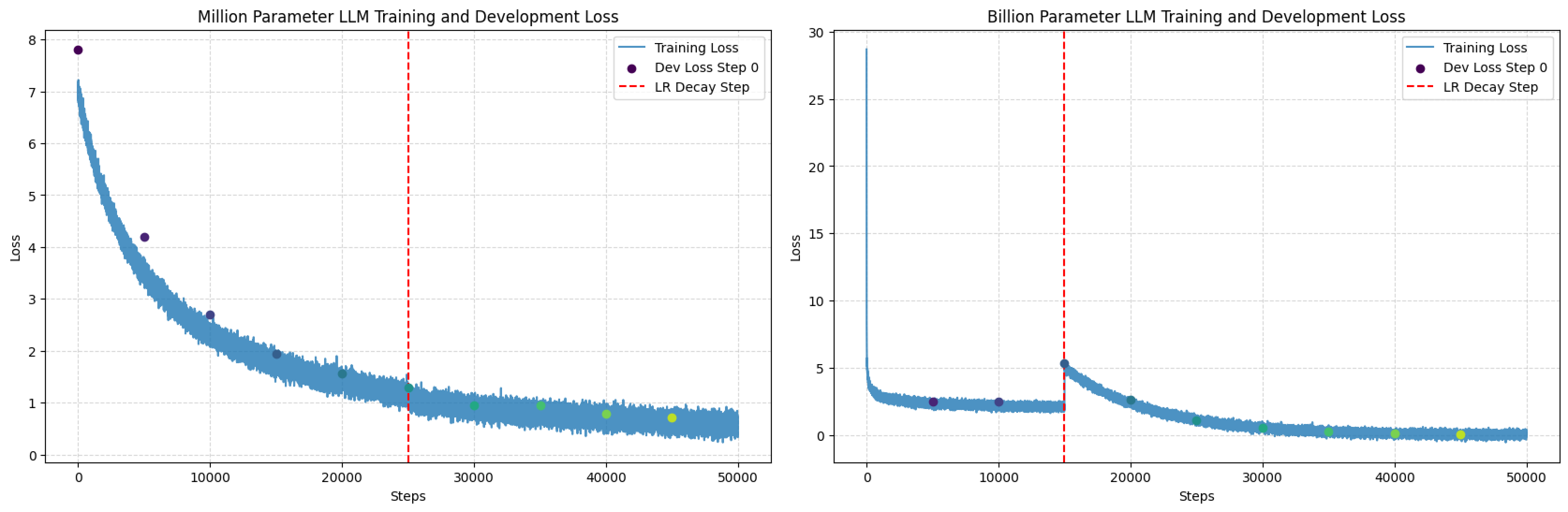
首次训练建议使用小型语料(如Tiny Shakespeare),1小时内即可看到模型从胡言乱语逐步生成合理诗句。完整训练WikiText等标准数据集约需12–48小时(视GPU型号而定)。
项目信息
A straightforward method for training your LLM, from downloading data to generating text.
1.5k
今日 +168 stars today
Stars
242
Forks
Jupyter Notebook
MIT
编程语言:Jupyter Notebook(Python 3.8+)|GitHub Star 数:1463|开源协议:MIT|GitHub 项目地址
这不仅是一个代码仓库,更是一份诚意满满的AI教育礼物——没有炫技的工程包装,只有扎实的实现与坦诚的分享。如果你想告别“调包侠”身份,真正触摸大模型的脉搏,现在就是开始的最佳时机。