Open-LLM-VTuber 是一款开源的本地化 AI 虚拟主播系统,它把大语言模型(LLM)和 Live2D 动态立绘深度融合,让你无需动手、仅靠说话就能与 AI 进行自然对话——还能实时打断、实时回应、实时表情同步。它不依赖云端服务,所有计算都在你自己的电脑上完成,兼顾隐私性、低延迟与高自由度,是中文用户打造个性化 AI 伴侣的理想选择。
核心功能

- 全语音免手操作:支持全程语音唤醒、语音输入、语音输出(TTS),真正实现“动口不动手”的沉浸式交互体验。
- 智能语音中断(Voice Interruption):说话中途想改口?直接插话即可,AI 会立刻停止当前响应并重新理解你的新指令,像真人对话一样自然流畅。
- 本地 Live2D 面部驱动:通过摄像头实时捕捉你的微表情或语音节奏,驱动 Live2D 模型做出眨眼、点头、口型同步、情绪变化等细腻反应,告别“静态纸片人”。
- 跨平台本地运行:Windows/macOS/Linux 全支持,既可直接运行 Python 脚本,也提供 Docker 镜像和预编译二进制包,新手也能快速部署。
- 灵活对接各类 LLM:原生支持 Ollama(一键拉取 Llama 3、Qwen、Phi-3 等热门模型),也可接入本地 API(如 vLLM、Text Generation WebUI)、甚至联网模型(需自行配置),不绑定任何厂商。
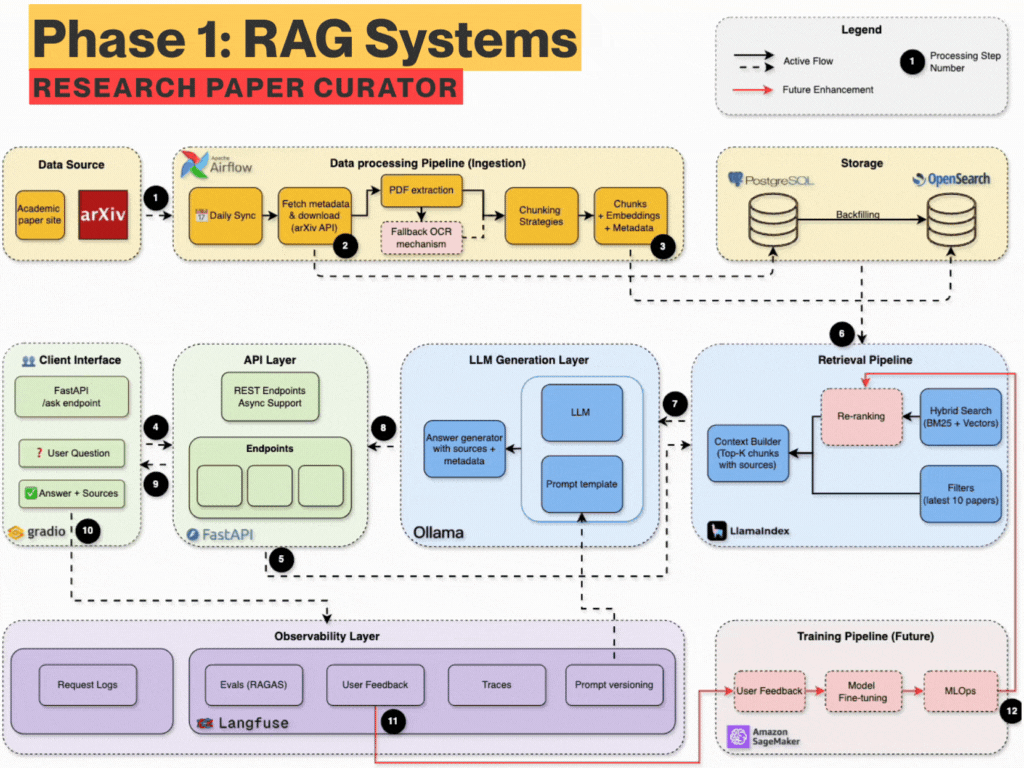
- 轻量易扩展架构:模块化设计(语音识别→LLM推理→TTS生成→Live2D渲染),每个环节均可替换优化,开发者可轻松集成 Whisper、Bark、RVC 变声、自定义动作逻辑等高级能力。
适合哪些人用
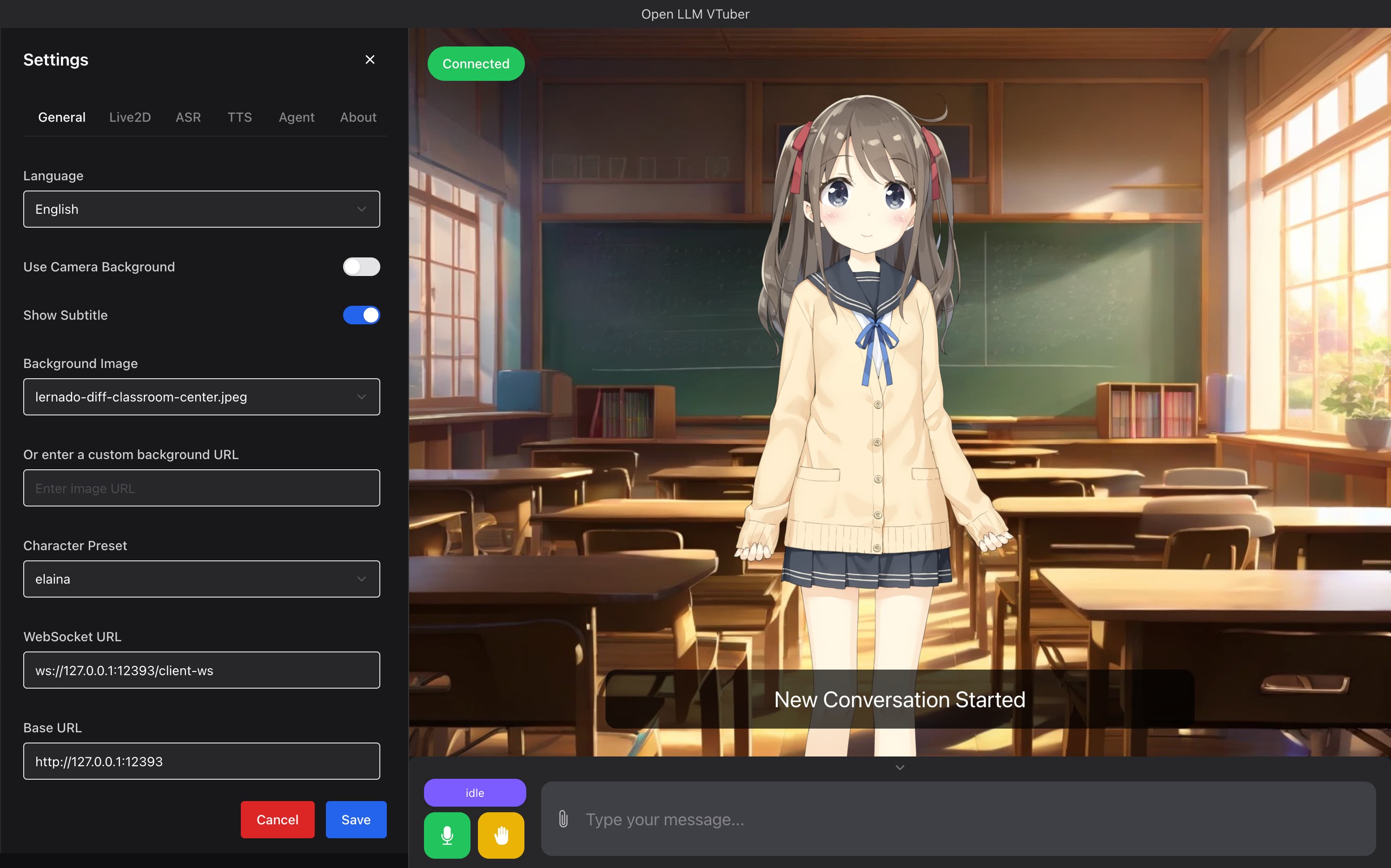
这款工具特别适合:AI 爱好者(想亲手搭建有温度的 AI 伙伴)、VTuber 创作者(低成本实现个人虚拟形象+智能互动)、教育/陪伴场景探索者(如语言陪练、老年陪伴、儿童启蒙)、隐私敏感用户(拒绝数据上传,所有语音与对话全程离线处理),以及 Python 开发者与开源贡献者(代码清晰、文档友好、社区活跃,v2.0 正在重构中,欢迎参与共建)。
快速上手
最简方式(推荐新手):
① 安装 Ollama(官方一键安装包);
② 终端执行 ollama run qwen2:1.5b 或 ollama run llama3 下载轻量模型;
③ 克隆项目:git clone https://github.com/Open-LLM-VTuber/Open-LLM-VTuber.git;
④ 进入目录,安装依赖:pip install -r requirements.txt;
⑤ 启动应用:python main.py —— 浏览器自动打开控制台,开启麦克风,选好模型和 Live2D 模型,即刻开聊!
💡 小贴士:项目提供 QQ 用户群(792615362)和 Zulip 开发社区,遇到问题秒回解答;Docker 用户可直接 docker run -p 8080:8080 open-llm-vtuber/open-llm-vtuber 一键启动。
项目信息
Talk to any LLM with hands-free voice interaction, voice interruption, and Live2D taking face running locally across platforms
8.7k
今日 +66 stars today
Stars
1.1k
Forks
Python
NOASSERTION
编程语言:Python|GitHub Star 数:8698|开源协议:未明确声明(NOASSERTION,建议使用前查阅仓库 LICENSE 文件)|GitHub 项目地址
如果你厌倦了冷冰冰的聊天框,渴望一个能听、能说、能笑、能思考,且完全属于你的 AI 虚拟伙伴——Open-LLM-VTuber 就是目前中文生态中最成熟、最易用、也最有生命力的本地化解决方案。