你是否想过,AI也能像生物学家一样理解蛋白质——这个构成生命的基础“分子机器”?Biohub 推出的 ESM 系列项目,正是一套面向蛋白质生物学的“世界模型”(World Model),它不是单一工具,而是一个融合语言理解、结构预测与知识图谱的科学智能引擎。它从数十亿天然蛋白质序列中自主学习进化规律,不仅能精准预测未知蛋白的三维结构,还能辅助设计全新功能蛋白,甚至揭示跨越数亿年的分子演化逻辑。对科研人员而言,这相当于为生命科学装上了新一代“AI显微镜”和“AI设计台”。
核心功能

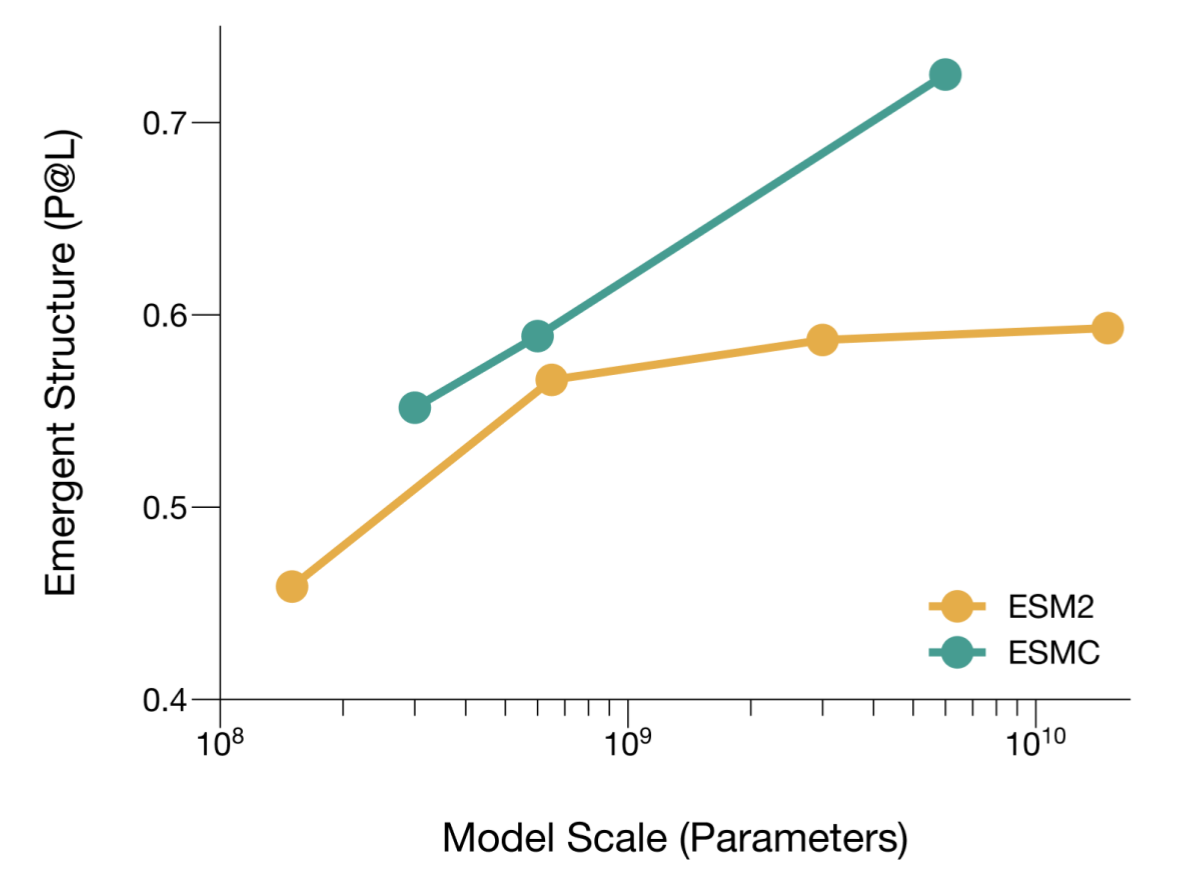
- 超大规模蛋白语言模型 ESMC:基于60亿参数架构,远超前代ESM2,在长程结构关系建模(如远程氨基酸相互作用)上实现突破性提升,真正理解“序列如何决定功能”。
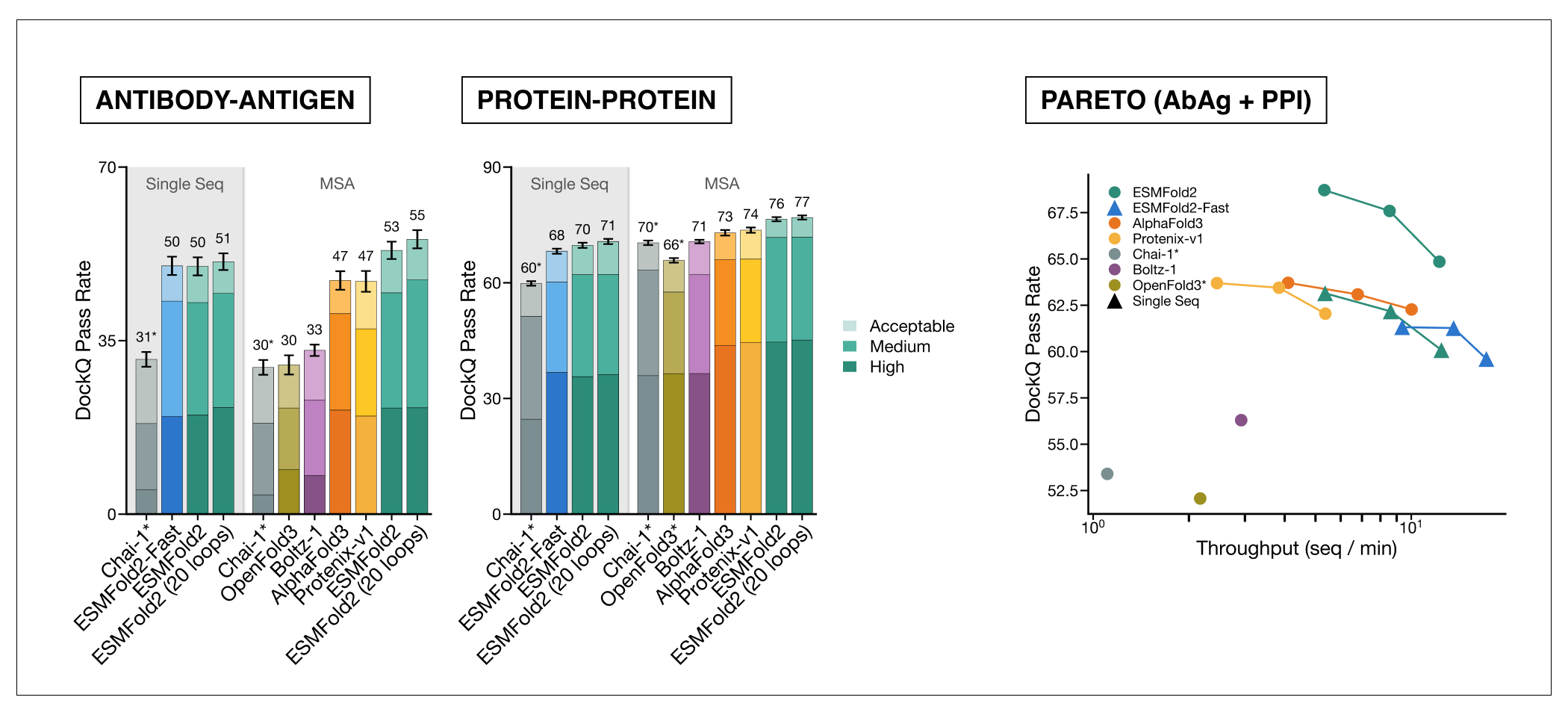
- 高精度结构预测神器 ESMFold2:直接调用ESMC 6B作为底层表示,在Hugging Face开源即用;无需MSA(多序列比对),单序列秒级输出原子级3D结构,精度媲美AlphaFold2,但速度更快、门槛更低。
- 交互式知识平台 ESM Atlas:在线访问超千万蛋白的嵌入向量、结构预测、功能注释与进化关联图谱,支持语义搜索(例如“找与胰岛素结构相似但更稳定的变体”)。
- 端到端蛋白设计工作流:从“指定功能→生成候选序列→折叠验证→优化稳定性”全流程可编程,已在抗体工程、酶改造等场景验证有效。
- 开源教程即学即用:提供Jupyter Notebook形式的实战指南,涵盖结构预测、嵌入可视化、突变效应分析、跨物种同源建模等高频科研任务。
- 社区驱动持续进化:活跃Slack社区(超千名研究者)实时交流技巧、共享提示词(prompt)、协作调试,避免“闭门造车”。
适合哪些人用
本项目专为生命科学领域的实践者打造:高校与研究所的计算生物学、结构生物学、合成生物学方向的研究生与青年PI;药企/生物技术公司的蛋白工程师、抗体研发人员、AI for Science团队;以及具备基础Python能力、希望将前沿AI深度融入实验设计的湿实验科学家。无需成为深度学习专家,但需熟悉生物序列与结构基本概念。
快速上手
零配置体验推荐使用ESM Atlas在线平台——上传FASTA文件或输入序列,30秒内查看预测结构与功能洞察。本地部署则极简:
pip install esm → 加载预训练模型 → 5行代码完成结构预测(示例见GitHub tutorials目录)。ESMFold2也已发布于Hugging Face Hub(Biohub/ESMFold2),支持transformers库直接调用。
项目信息
Biohub/esm
GitHub
2.6k
今日 +64 stars today
Stars
313
Forks
Jupyter Notebook
NOASSERTION
编程语言:Jupyter Notebook(主教程)、Python(核心库)| GitHub Star 数:2557| 开源协议:未明确声明(NOASSERTION),但所有模型权重与代码均免费开放商用| GitHub 项目地址
如果你正在为蛋白结构难测、设计周期太长、进化关系难梳理而困扰,ESM 系列就是那个把“生物学直觉”翻译成AI语言的桥梁——它不取代实验,却让每一次实验都更接近答案。