你是否曾被动辄百万美元的 LLM 预训练成本劝退?HRM-Text 是一个真正“平民化”的开源大模型项目——它用不到 1000 美元的算力预算,就能在 2 天内从零开始预训练一个 10 亿参数(1B)的高质量文本生成模型。它不依赖超大规模数据与千卡集群,而是通过创新的分层推理架构(HRM)和高效训练工程,将预训练门槛大幅降低,让高校实验室、小团队甚至资深个人开发者,第一次拥有了自主构建基础模型的能力。
核心功能

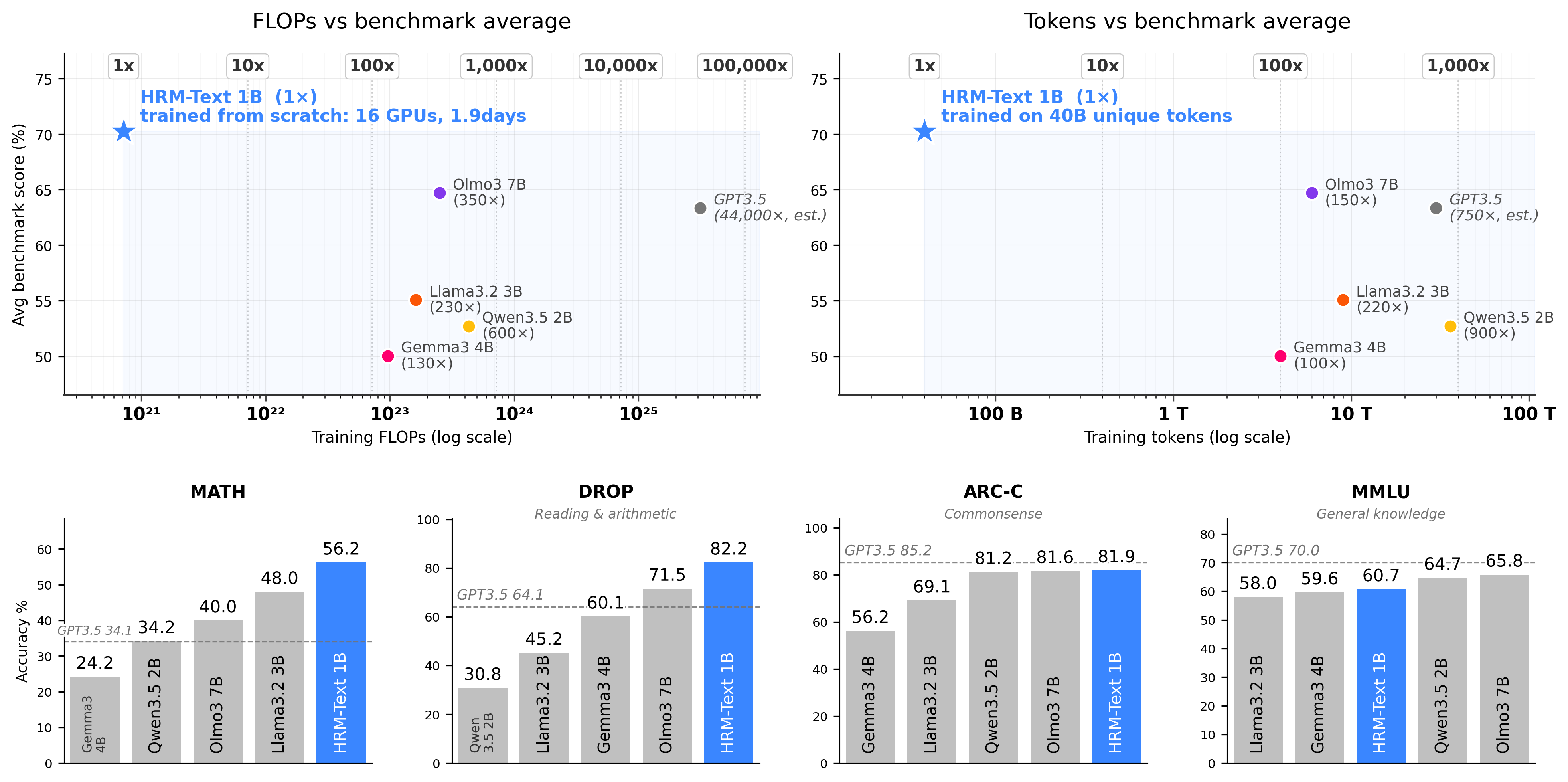
- 极低成本预训练框架:实测仅需 8–16 块 H100 GPU,46–50 小时即可完成 1B 模型完整预训练,算力消耗仅为传统方案的 1/130~1/600,数据需求减少 150–900 倍
- 原创 HRM 分层推理架构:突破标准 Transformer 的扁平结构,引入层级化循环机制与潜在空间推理模块,在保持轻量的同时显著提升逻辑推理与长程依赖建模能力
- 工业级训练栈集成:开箱即用支持 FlashAttention-3、PyTorch FSDP2(第二代全分片数据并行)、PrefixLM 序列打包等前沿优化,兼顾速度、显存与扩展性
- 端到端工具链完备:内置数据预处理、分布式训练脚本、多维度评估(GSM8K/MATH/DROP/MMLU 等)、Hugging Face 模型导出与格式转换工具,无需额外拼接生态
- 高性能轻量推理支持:1B 参数模型在单张消费级旗舰卡(如 RTX 4090)上可实现流畅对话与代码补全,支持量化部署与 API 封装
- 学术友好、完全透明:配套论文已公开于 arXiv,所有训练超参、数据清洗策略、评估细节均在 GitHub 仓库详尽披露,复现无黑盒
适合哪些人用
如果你是高校 NLP 方向的研究生或青年教师,想在有限实验室经费下开展大模型基础研究;如果你是创业公司 AI 工程师,需要定制垂直领域基座模型但无力承担百万元训练成本;如果你是技术极客或开源贡献者,希望深入理解大模型训练全流程而非仅调用 API——HRM-Text 正是为你而生。它不是另一个“微调玩具”,而是一个真实可用、可修改、可复现、可进化的工业级预训练基础设施。
快速上手
只需三步即可启动训练或推理:
- 安装依赖:运行
pip install -r requirements.txt(需 CUDA 12.1+、PyTorch 2.3+、FlashAttention-3) - 一键加载模型:使用 Hugging Face 接口直接调用已发布权重:
from transformers import AutoModelForCausalLM; model = AutoModelForCausalLM.from_pretrained("sapientinc/HRM-Text-1B") - 启动预训练(可选):按文档配置
config/train_xl.yaml,执行torchrun --nproc_per_node=8 train.py --config config/train_xl.yaml即可分布式启动 1B 模型训练
详细教程、数据准备指南与故障排查清单见项目 README 和 docs/ 目录。
项目信息
📦
sapientinc/HRM-Text
GitHub
sapientinc/HRM-Text
GitHub
HRM-Text is a 1B text generation model based on the HRM architecture, strengthened by task completion and latent space reasoning.
编程语言:Python|GitHub Star 数:651|开源协议:Apache-2.0|GitHub 项目地址
HRM-Text 不是“又一个 LLM”,而是一把打开大模型自主权之门的钥匙——它用扎实的工程与清醒的学术判断证明:强大,不必昂贵;创新,可以普惠。