VibeVoice 是微软推出的全新开源语音 AI 套件,它不是单一工具,而是一套覆盖“说”与“听”全链路的语音智能解决方案——既能生成自然流畅、富有情绪和个性的合成语音(TTS),也能高精度识别中英文等多语种语音并实时转文字(ASR)。它专为解决开发者、创作者和普通用户在语音交互场景中的核心痛点而生:传统语音工具音色机械、响应迟滞、方言支持弱、部署复杂。VibeVoice 用前沿模型+开箱即用设计,让高质量语音能力真正平民化。
核心功能
![]()
- 沉浸式情感语音合成(StreamingTTS):支持流式低延迟生成,可调节语速、停顿、重音甚至“语气倾向”(如亲切、专业、活泼),告别机器人腔;已预置中文普通话、粤语、英语、日语、韩语等10+语种音色。
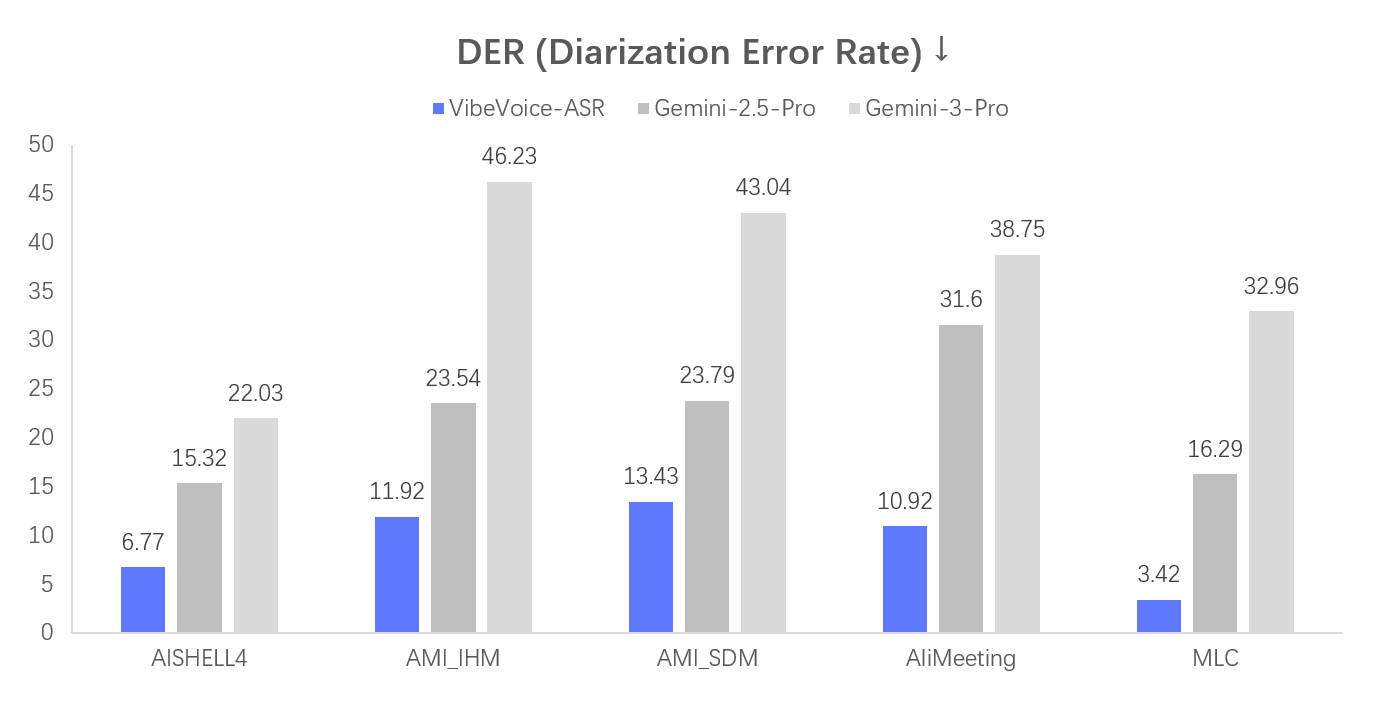
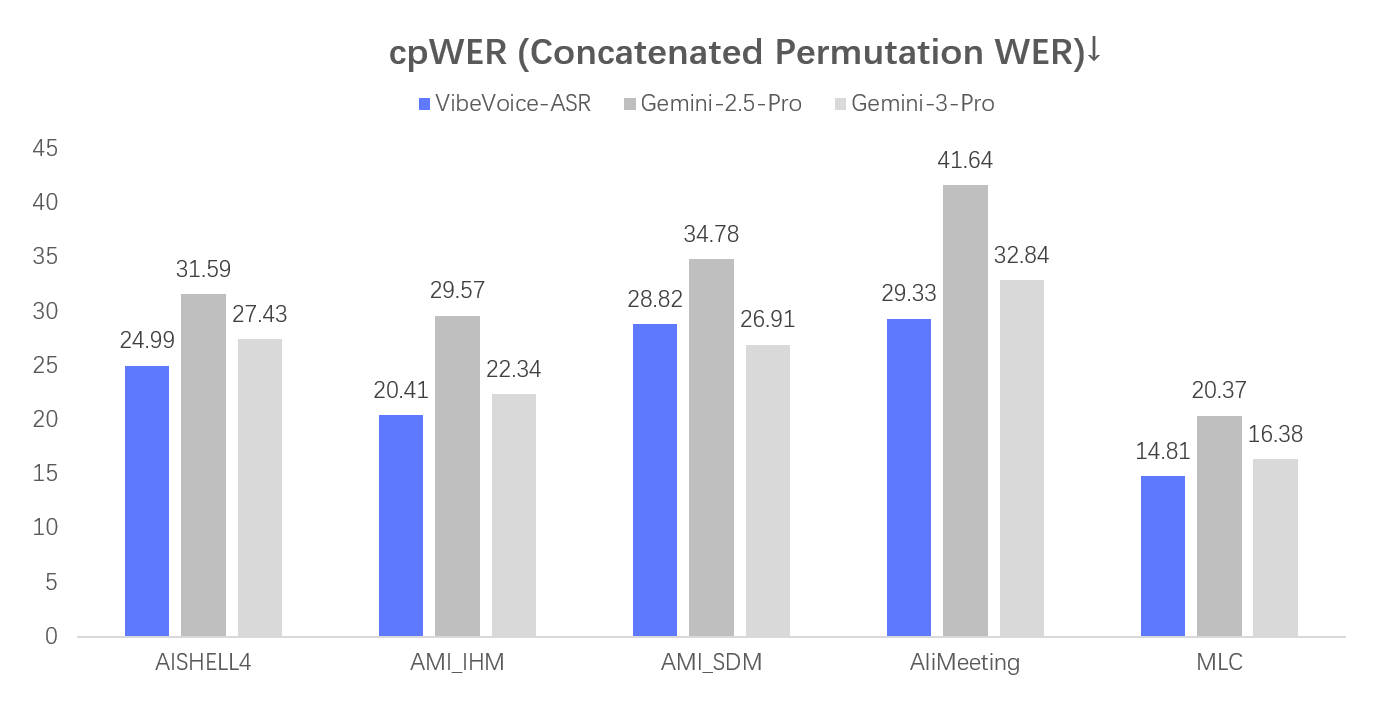
- 高鲁棒性语音识别(VibeVoice-ASR):在嘈杂环境、带口音、快语速、中英混说等真实场景下仍保持95%+准确率,支持实时流式识别与离线模式,适配会议记录、课堂笔记、无障碍输入等刚需场景。
- 零代码体验入口:官方提供 Hugging Face 模型集、Gradio ASR 交互演示页(在线试听/试说)和 Google Colab 一键运行笔记本,无需配置环境即可30秒体验全部能力。
- 轻量可嵌入架构:核心模型经量化压缩,可在消费级显卡(如RTX 3060)或Mac M1/M2芯片上本地运行,支持Python API调用,轻松集成进App、智能硬件或网页应用。
- 开放模型与训练框架:完整开源训练脚本、数据处理流程及微调指南,支持用户用自定义音频数据(如企业客服录音、个人播客)快速定制专属语音模型。
- 中文深度优化:针对中文四声调、儿化音、轻声词、网络热词等特性专项优化,TTS自然度媲美专业配音,ASR对“微信语音”“地铁报站”“直播间话术”等典型中文语音泛化能力强。
适合哪些人用
独立开发者:快速为AI应用添加语音交互层,避免采购商业API的高昂成本与合规风险;内容创作者:批量生成有表现力的短视频旁白、有声书、课程讲解;教育科技团队:构建口语评测、实时字幕、听障辅助系统;中小型企业:定制客服语音应答、内部会议纪要助手;高校研究者:基于高质量基线模型开展语音合成、端到端语音理解等前沿课题;甚至普通用户——下载基于VibeVoice-ASR打造的开源输入法Vibing,就能用语音直接打字聊天、写文档、发消息。
快速上手
最简方式:打开 ASR Playground 点击麦克风说话,立刻看到文字输出;或运行 Colab Notebook,上传一段音频,5行代码生成带情感的语音。
本地部署(推荐):
- 安装依赖:
pip install vibevoice(需Python 3.9+、PyTorch 2.3+) - 下载预训练模型:
vibevoice download --model tts-zh-cn --output ./models - 一行代码合成语音:
vibevoice tts --text "你好,今天天气真不错!" --model ./models/tts-zh-cn --output output.wav - 语音识别同理:
vibevoice asr --audio input.mp3 --lang zh-CN
详细教程、API文档与微调指南见项目 README,所有示例均附中文注释。
项目信息
Open-Source Frontier Voice AI
⭐
27.1k
今日 +1,190 stars today
Stars
27.1k
今日 +1,190 stars today
Stars
🔀
3.0k
Forks
3.0k
Forks
Python
📄
MIT
MIT
编程语言:Python|GitHub Star 数:27118|开源协议:MIT|GitHub 项目地址
这是目前中文社区最易用、最扎实、且真正“开箱即战”的开源语音AI项目——不画大饼,不堆参数,只交付能立刻跑起来、听得清、说得像的生产力工具。