Unlimited-OCR 是百度推出的全新开源OCR(光学字符识别)系统,它不再满足于逐行或分块识别文字,而是真正实现了“一图一命、全局理解”的长程文档解析能力。面对扫描PDF、学术论文、财务报表、多栏报刊等结构复杂、跨页连续的文档,传统OCR常出现错位、漏字、逻辑断裂等问题;而 Unlimited-OCR 通过端到端建模,首次在开源领域支持“单次输入、全页语义连贯输出”,让机器像人一样“通读一页再下笔整理”。它不是OCR的简单升级,而是迈向“文档智能体”的关键一步。
核心功能

- 一图到底,长程上下文感知:支持超长横向/纵向图像(如A0工程图、百页PDF截图),模型自动建模跨区域语义关联,避免表格跨页断裂、公式编号错乱等问题。
- 原生支持多模态结构还原:不仅能提取文字,还能同步识别标题层级、段落归属、列表缩进、表格线框、数学公式(LaTeX格式)、脚注引用关系,并保持原始阅读顺序。
- 零样本适配新文档类型:基于强大的视觉-语言联合表征,对从未见过的版式(如古籍竖排、医疗检验单、海关报关单)也能实现高质量解析,无需重新训练或标注。
- 开箱即用的Hugging Face集成:提供预训练模型
baidu/Unlimited-OCR,一行代码即可加载,兼容Transformers生态,支持GPU加速推理。 - 轻量部署友好:默认使用Qwen-VL风格的高效ViT-LLM架构,在单张RTX 4090上可实现15秒内完成一页A4扫描件的全要素解析(含表格+公式)。
- 开放可复现的研究基线:配套发布完整训练流程、评估协议(UNLIMITED-BENCH)及可视化分析工具,助力学术界推进文档智能前沿研究。
适合哪些人用
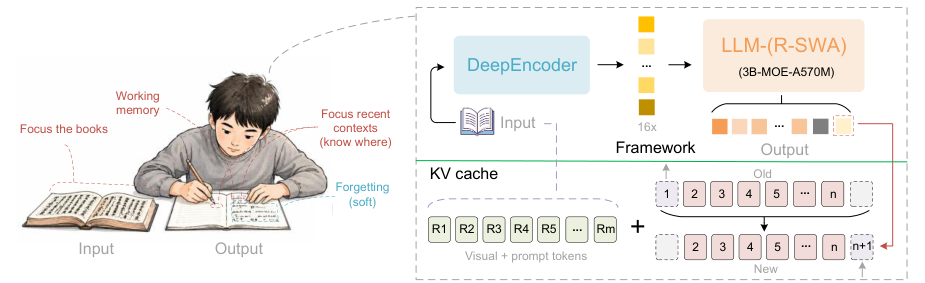
高校与研究所的NLP/文档智能方向研究者;需要批量处理合同、发票、论文、专利等非结构化文档的企业IT与RPA工程师;数字出版、古籍数字化、教育科技公司的内容中台团队;以及所有厌倦了“切图→OCR→人工校对→重排版”三步苦工的技术型产品经理和开发者。如果你曾为PDF复制粘贴后满屏乱码、表格错行、参考文献序号飞走而深夜叹气——这正是为你准备的工具。
快速上手
只需3步,5分钟内跑通首个案例:
- 安装依赖(推荐Python 3.12 + CUDA 12.9):
pip install torch==2.10.0 torchvision==0.15.0 transformers==4.41.0 Pillow opencv-python - 加载模型并解析本地图片:
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
processor = AutoProcessor.from_pretrained("baidu/Unlimited-OCR")
model = AutoModelForSeq2SeqLM.from_pretrained("baidu/Unlimited-OCR")
image = Image.open("sample.pdf") # 支持PDF、PNG、JPG
inputs = processor(images=image, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=2048)
text = processor.decode(outputs[0], skip_special_tokens=True)
print(text) - 进阶使用:访问Hugging Face模型页下载ONNX量化版本,或参考GitHub仓库中的CLI工具与Flask API示例一键部署为Web服务。
项目信息
📦
baidu/Unlimited-OCR
GitHub
baidu/Unlimited-OCR
GitHub
Unlimited OCR Works: Welcome the Era of One-shot Long-horizon Parsing.
⭐
400
400
Stars
🔀
32
Forks
32
Forks
Python
📄
MIT
MIT
编程语言:Python|GitHub Star 数:400|开源协议:MIT|GitHub 项目地址
它用开源的方式,把过去只有大厂私有系统才有的“整页级文档理解”能力,交到了每个开发者手中。