UniRL 是腾讯混元团队推出的开源强化学习(RL)训练框架,专为统一架构的多模态大模型(如图文生成、语音合成、扩散模型、自回归模型等)设计。它不再要求为每种模型结构(Diffusion、AR、PE、Unified)单独开发RL训练流水线,而是用一套标准化的“采样→打分→计算优势→策略更新→权重同步”闭环,支撑跨模态、跨范式的强化学习后训练。解决了当前多模态AI研发中RL适配成本高、代码重复、算法复用难的核心痛点。
核心功能
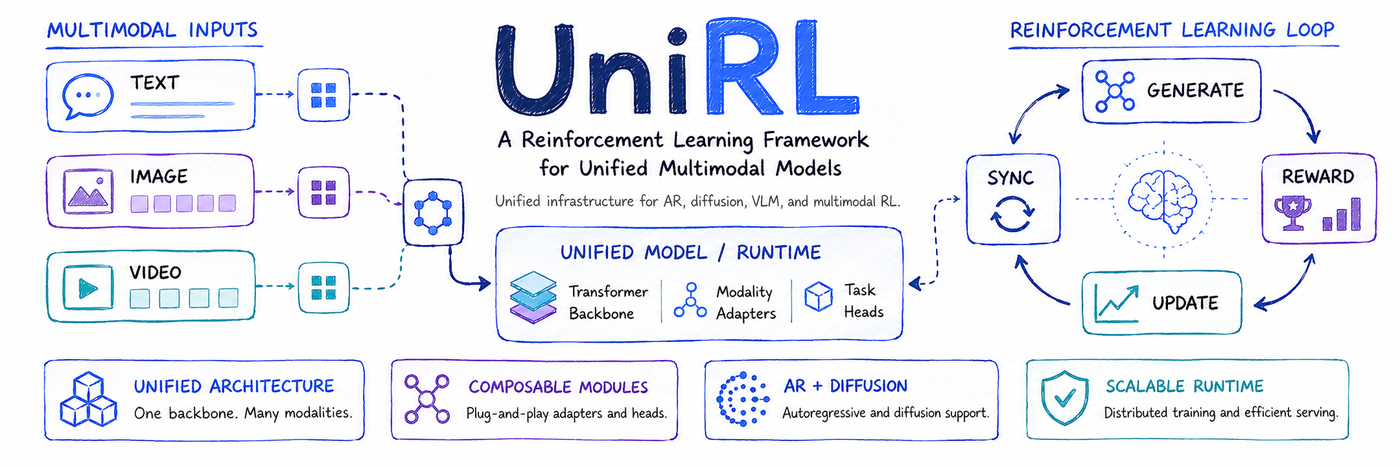
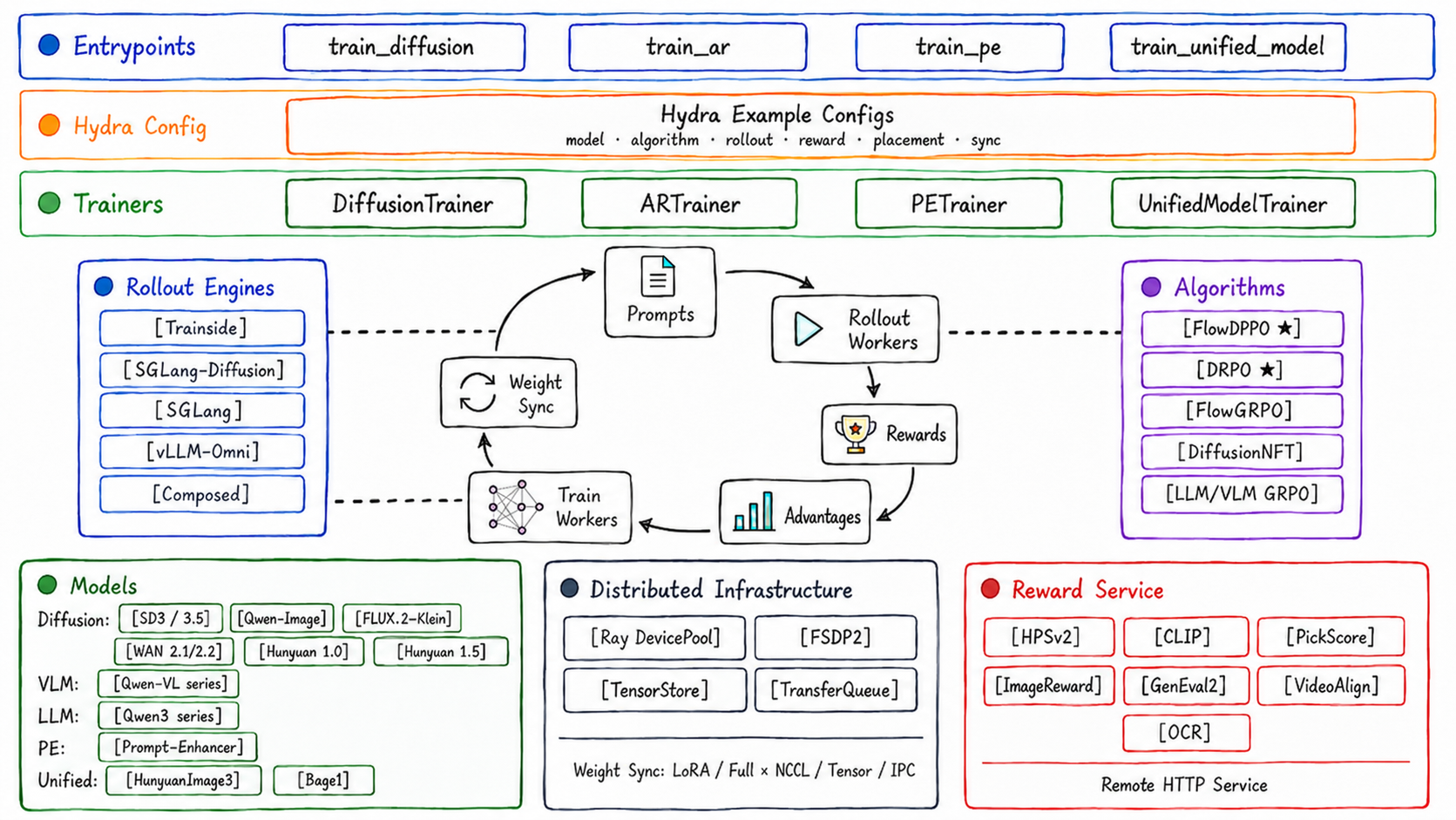
- 真正统一的RL训练接口:提供
train_diffusion、train_ar、train_pe、train_unified_model四大入口,底层共享同一套RL引擎,避免重复造轮子 - 开箱即用的前沿算法实现:已集成腾讯最新发布的 DRPO(发散正则化优化)和 Flow-DPPO(面向流匹配模型的近端策略优化),全部开源并附论文链接
- Hydra 配置驱动,灵活可扩展:所有模型结构、奖励函数、采样策略、优化器参数均通过 YAML 配置文件定义,支持快速实验迭代与复现
- 模块化 rollout 与 reward 系统:支持本地/远程 rollout worker 分布式采样,兼容自定义奖励模型(RM)、人类反馈(HF)、规则打分等多种评估方式
- 多模态原生支持:从输入编码、隐空间对齐到跨模态动作空间建模,框架底层已适配图像、文本、音频等异构数据联合训练需求
- 生产级工程设计:内置梯度检查点、混合精度训练、CPU/GPU/TPU 多后端支持,并提供完整文档站与微信交流群支持
适合哪些人用
UniRL 主要面向三类技术实践者:一是多模态大模型研究员,希望在图文生成、视频理解、语音合成等任务上探索 RLHF/RLAIF 新范式;二是强化学习工程师,需要将 PPO、DPPO、DRPO 等算法快速迁移到 Diffusion 或流匹配模型上;三是高校与实验室学生,想基于工业级框架复现顶会论文、开展毕业课题或竞赛项目——无需从零搭建分布式RL训练系统,专注算法创新本身。
快速上手
只需三步即可启动训练:
- 安装依赖:
pip install unirl(推荐 Python 3.12+ 环境) - 选择示例配置:
cd configs/train_diffusion/ && ls,例如加载sd3.yaml或flow_matching.yaml - 一键训练:
python -m unirl.train_diffusion --config-path configs/train_diffusion --config-name sd3
详细教程、API 文档与 Jupyter 示例见官方文档站:https://unirl-project.github.io/unirl/,遇到问题还可扫码加入微信技术交流群获取一线支持。
项目信息
UniRL is a Framework for Unified Multimodal Model Reinforcement Learning
⭐
479
479
Stars
🔀
27
Forks
27
Forks
Python
📄
NOASSERTION
NOASSERTION
编程语言:Python|GitHub Star 数:479|开源协议:Apache-2.0|GitHub 项目地址
如果你正在为多模态模型的强化学习调优反复写样板代码,UniRL 就是那个帮你省下 80% 工程时间、把精力聚焦在算法突破上的「RL 操作系统」。