你是否曾为LLM的上下文窗口焦头烂额?RAG检索出20页文档、Agent日志堆满屏幕、调试时输出几百行JSON——结果发现90%的内容对回答毫无帮助,却白白消耗昂贵的token?Headroom正是为此而生:它不是简单删减,而是在不损失关键信息的前提下,对提示词(prompt)、日志、文件、RAG分块等各类输入进行智能语义压缩,实测可减少60%–95%的token用量,且最终回答质量几乎完全一致。它像一位经验丰富的“上下文编辑总监”,默默为你精简冗余、保留精华,让大模型真正聚焦在该关注的地方。
核心功能

- 多模态输入压缩:支持压缩文本日志、代码文件、Markdown文档、JSON结构化数据、RAG检索返回的chunk片段,甚至Cursor/VS Code插件中的实时上下文流。
- 6种工业级压缩算法:内置包括语义摘要(基于Kompress-base微调模型)、关键句提取、冗余段落剔除、结构化剪枝(如只保留函数签名+docstring)、LLM引导式重写、以及无损可逆编码等多种策略,可按场景灵活组合或切换。
- 三合一部署模式:既可作为Python库直接集成到LangChain、LlamaIndex或自研Agent中;也可启动本地FastAPI代理服务,无缝拦截OpenAI/Claude/Anthropic等API请求并自动压缩;还支持MCP(Model Context Protocol)标准,与新一代AI开发工具链原生协同。
- 完全可逆 & 本地优先:所有压缩操作均保留原始数据指纹和解压元信息,必要时可一键还原原始上下文,保障调试与审计可靠性;默认不上传任何数据至云端,敏感业务场景安心可用。
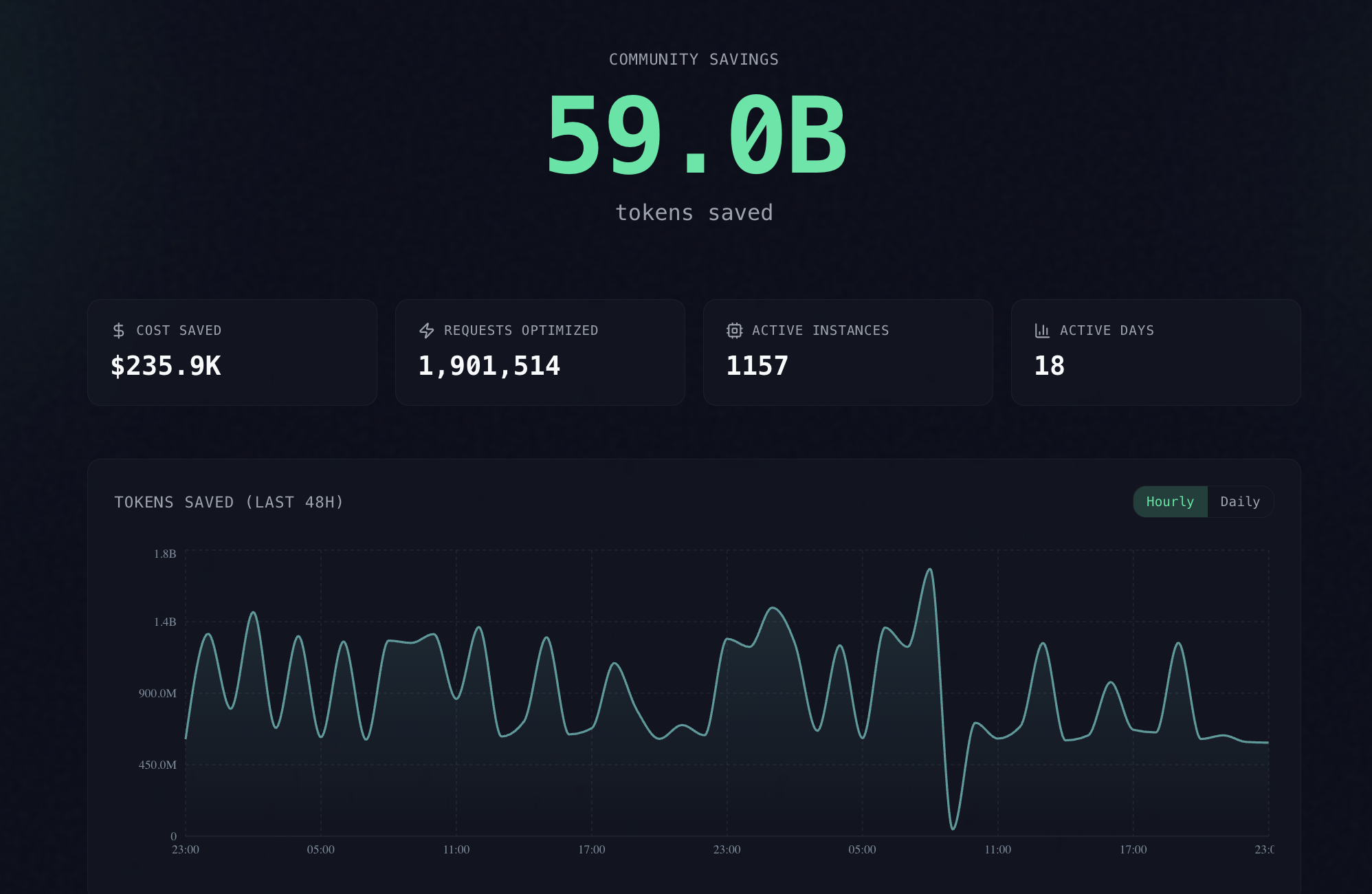
- 开箱即用的可观测性:提供Dashboard(headroomlabs.ai/dashboard)实时查看token节省量、压缩率分布、各算法命中率,助你持续优化提示工程策略。
- 跨语言友好:Python主库已成熟稳定,同时发布TypeScript/NPM包,前端Agent、浏览器插件、Node.js后端均可快速接入。
适合哪些人用
如果你是以下角色之一,Headroom将显著提升你的开发效率与成本效益:
- AI应用工程师:正在构建RAG问答系统、智能客服、自动化报告生成等产品,苦于上下文超限或token成本过高;
- Agent框架开发者:使用LangChain、LlamaIndex、AutoGen或自研Agent架构,希望在不改核心逻辑前提下提升上下文利用率;
- 大模型运维/平台工程师:负责LLM网关、API代理层建设,需统一管控输入质量、降低推理负载、增强稳定性;
- 提示工程师与LLM研究员:探索context engineering新范式,需要可复现、可度量、可对比的压缩基线工具。
快速上手

安装只需一行命令:
pip install headroom-ai
三分钟体验压缩效果:
# Python库方式(适用于集成进现有流程)
from headroom import Compressor
compressor = Compressor(algorithm="semantic_summarize")
compressed = compressor.compress("你的长文本输入...")
print(f"压缩前{len(input)}字符 → 压缩后{len(compressed)}字符,token节省约78%")
或启动本地代理(兼容OpenAI SDK):
headroom-proxy --port 8000 --upstream https://api.openai.com/v1
然后将你的OpenAI客户端base_url指向http://localhost:8000,所有请求自动压缩传输,无需修改一行业务代码。
项目信息
Compress tool outputs, logs, files, and RAG chunks before they reach the LLM. 60-95% fewer tokens, same answers. Library, proxy, MCP server.
⭐
5.1k
今日 +1,266 stars today
Stars
5.1k
今日 +1,266 stars today
Stars
🔀
387
Forks
387
Forks
Python
📄
Apache-2.0
Apache-2.0
编程语言:Python(主库),含TypeScript支持
GitHub Star 数:5095
开源协议:Apache-2.0
GitHub 项目地址
Headroom不是又一个“玩具级”压缩脚本,而是已被多家AI原生团队用于生产环境的上下文基础设施——它用扎实的工程实现,把“少即是多”的提示工程哲学变成了可落地、可监控、可信赖的技术现实。