MOSS-TTS 是由 MOSI.AI 与 OpenMOSS 团队联合推出的开源语音生成模型家族,不是传统 TTS 的简单升级,而是一套面向真实场景的“全栈式声音操作系统”。它专为解决中文用户长期面临的痛点而生:合成语音机械呆板、长文本断句混乱、多人对话缺乏角色区分、无法定制专属声线、环境音效缺失、以及实时交互延迟高等问题。无论你是想为有声书生成自然停顿的百页朗读,为游戏角色赋予性格鲜明的声音,还是在直播中实时合成带背景雨声的旁白,MOSS-TTS 都提供了开箱即用的高质量方案。
核心功能
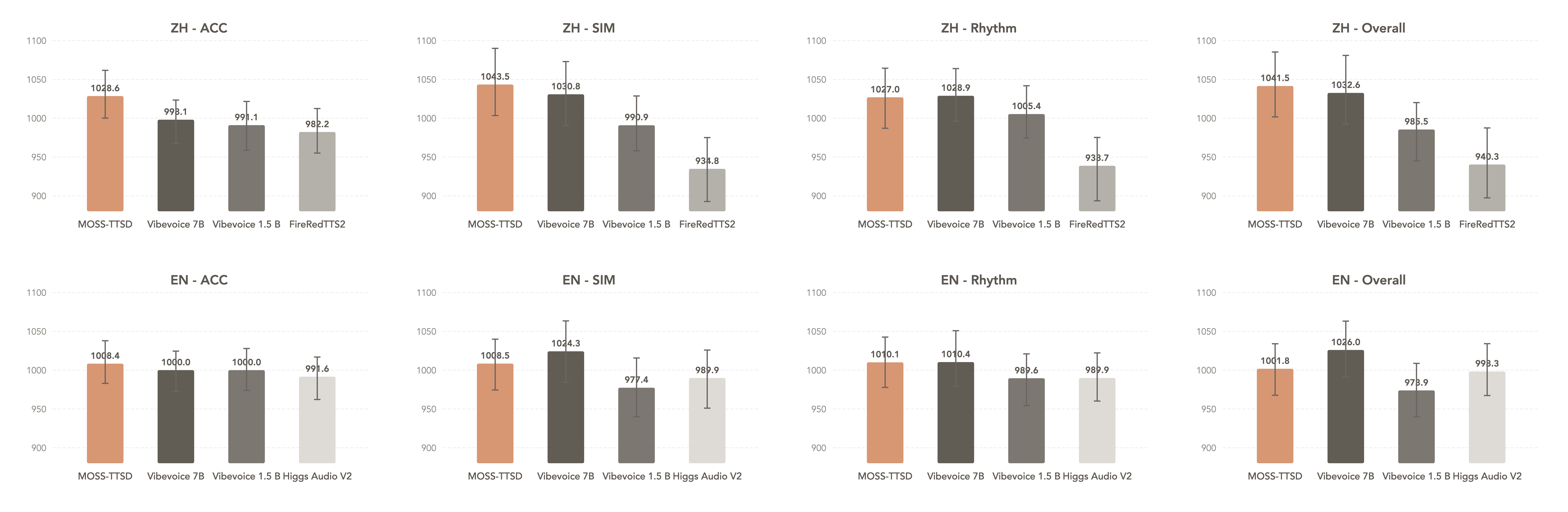
- 超长文本稳定合成:支持万字以上连续文本生成,自动处理语义断句、呼吸停顿与情感节奏,告别“念经式”输出,语音流畅度媲美专业播音员。
- 多说话人智能对话系统:内置多角色声线库(含男/女/少年/老年等),支持同一段脚本中自动切换说话人,并保持语气连贯、情绪一致,轻松制作广播剧、客服对话或教育课件。
- 零样本声音克隆与角色设计:仅需 30 秒目标人声样本,即可克隆其音色、语调甚至微表情式语气;更支持“拟人化参数调节”(如“沉稳中带笑意”“语速稍快带科技感”),打造专属虚拟主播或IP声优。
- 语音+环境音效协同生成:全球少有的将语音与环境声(如咖啡馆嘈杂声、地铁报站回响、森林鸟鸣)联合建模的开源模型,可精准控制声效强度、空间位置与时间对齐,一键生成沉浸式音频内容。
- 低延迟流式TTS服务:提供毫秒级响应的实时语音合成API,支持边输入边发声(Streaming TTS),适用于语音助手、实时字幕配音、AI会议纪要等强交互场景。
- 全中文深度优化架构:底层采用自研音频标记器(Audio Tokenizer)与多模态对齐技术,对中文四声调、轻声、儿化音、方言词等细节建模精细,发音准确率与自然度显著优于通用英文模型直译方案。
适合哪些人用
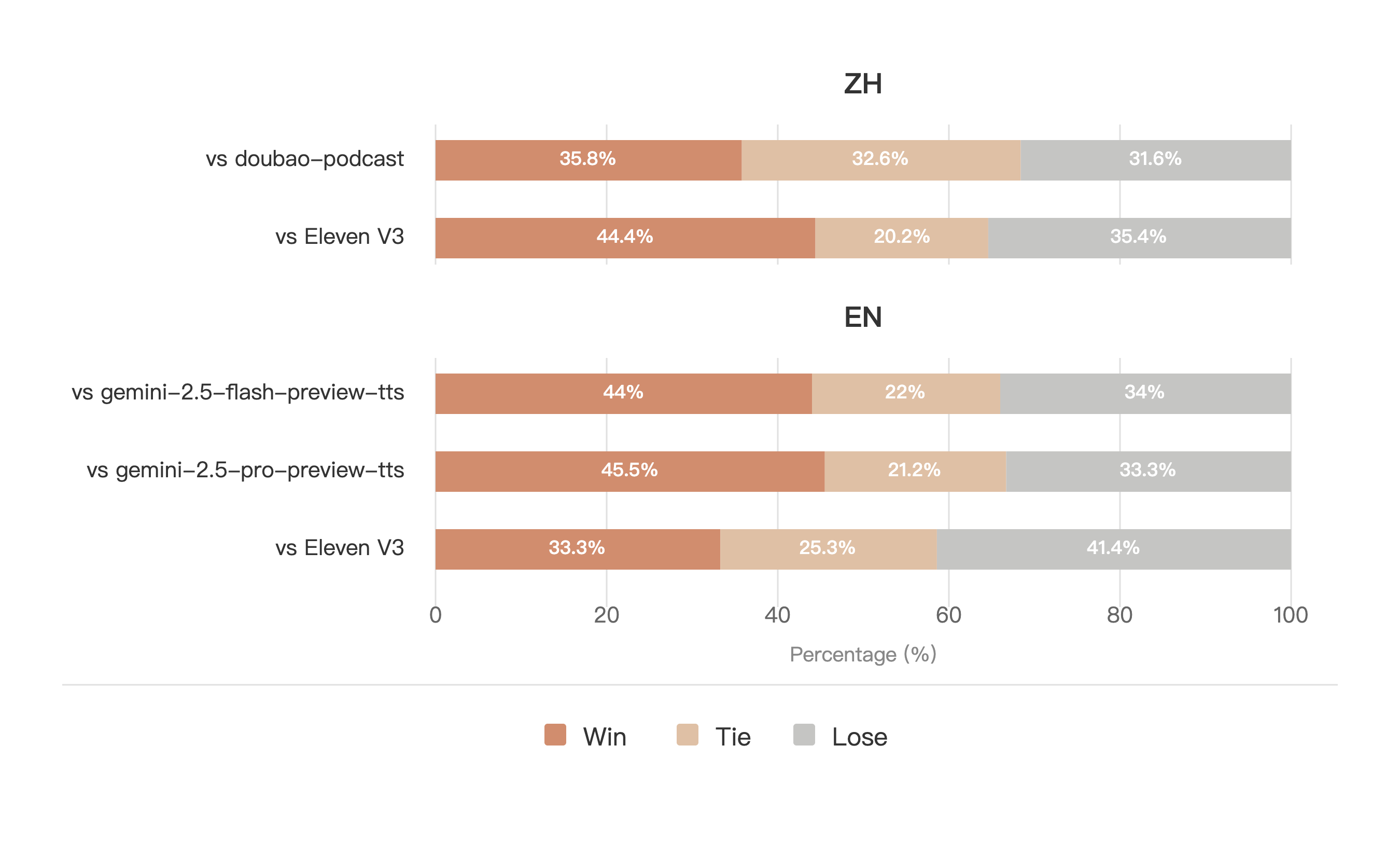
内容创作者(有声书、短视频配音、播客主)、教育科技公司(AI教师、语言学习APP)、游戏与元宇宙开发者(NPC语音、虚拟偶像)、无障碍产品团队(为视障用户提供高表现力语音反馈)、AIGC 工具开发者(集成到自己的创作平台中),以及所有希望摆脱“机器腔”、追求声音表现力的中文技术爱好者——只要你需要让文字“活起来”,MOSS-TTS 就是值得优先尝试的国产开源首选。
快速上手
![]()
无需从头训练!项目已提供预训练模型和极简调用接口:
- 安装依赖:
pip install moss-tts(支持 Python 3.9+) - 一行代码试听示例:
from moss_tts import MOSS_TTS; tts = MOSS_TTS(); tts.synthesize("你好,我是MOSS,一个会思考、会表达、还会配乐的声音伙伴。", output_path="hello.wav") - 进阶使用:通过 Hugging Face 或 ModelScope 下载指定模型(如
moss-tts-zh-multi多角色版),配合 API 文档快速接入 Web 服务或本地部署;官方 AI Studio(studio.mosi.cn)还提供免代码网页版体验,上传文本+选择角色,3秒出音频。
项目信息
MOSS‑TTS Family is an open‑source speech and sound generation model family from MOSI.AI and the OpenMOSS team. It is designed for high‑fidelity, high‑
2.6k
今日 +88 stars today
Stars
234
Forks
Python
Apache-2.0
编程语言:Python|GitHub Star 数:2573|开源协议:Apache-2.0|GitHub 项目地址
如果你厌倦了千篇一律的电子音,又苦于商业TTS授权贵、定制难、中文差——MOSS-TTS 这个真正为中文世界打磨、开源免费、功能完整且持续迭代的语音引擎,值得你立刻下载试试看。